


一、核心定义:单向流动的智能流水线
1. 基本概念
前馈(Feedforward):信号从输入层单向传递至输出层,无循环或反馈
全连接(Fully Connected):相邻层神经元两两相连,形成密集网络
通用近似定理:单隐藏层FNN即可逼近任意连续函数(需足够多神经元)
2. 与生物神经网络的简化类比

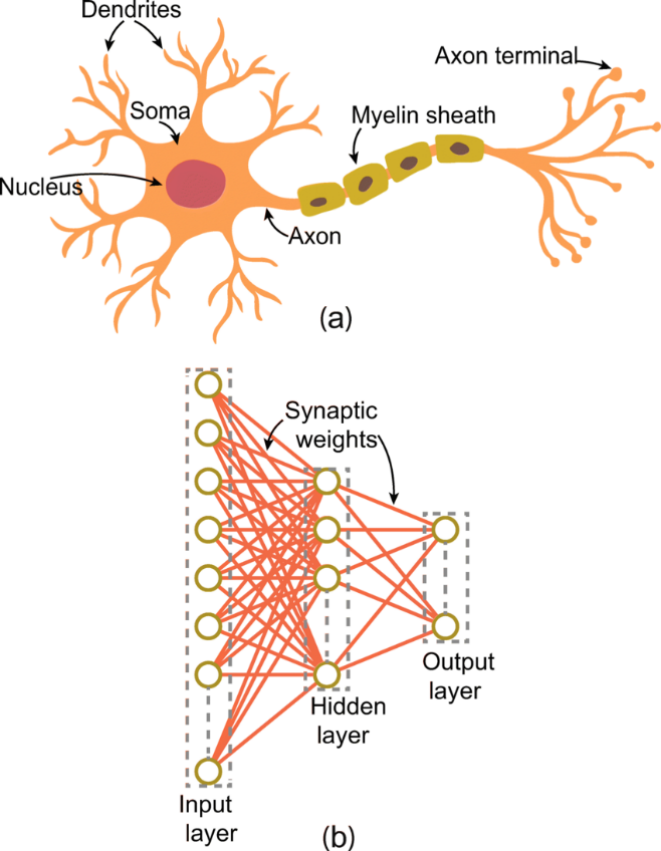
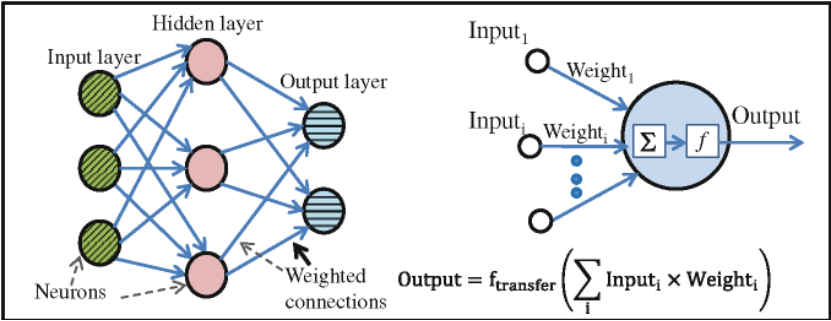
1. 层级架构详解
l输入层(Input Layer):
Ø神经元数量= 数据特征维度(如28×28图像→784个神经元)
Ø功能:原始数据接入(不进行运算)
l隐藏层(Hidden Layer):
Ø网络深度决定抽象能力(典型1-3层)
Ø每层神经元数可自由设计(超参数调优关键)
Ø示例:MNIST手写识别常用结构 [784, 256, 64, 10]
l输出层(Output Layer):
Ø二分类:1个神经元(Sigmoid激活)
Ø多分类:神经元数=类别数(Softmax激活)
Ø回归任务:直接输出连续值(无激活函数)
三、数学引擎:从线性叠加到非线性跃迁
1. 前向传播公式分解
设第l层权重矩阵为W(l),偏置向量为b(l),激活函数为
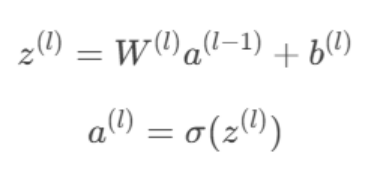
(单样本输入):

2.
激活函数:打破线性的魔法石
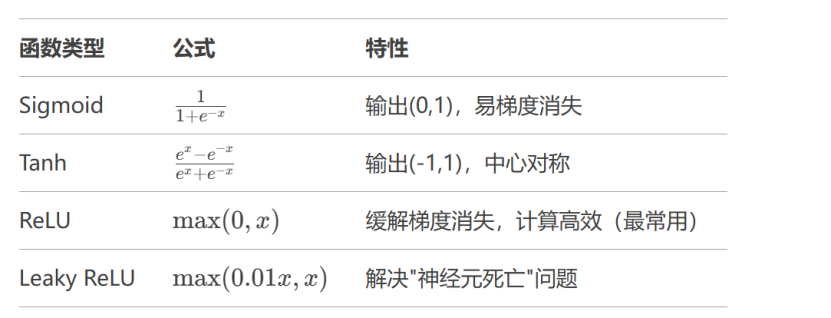
四、训练机制:误差驱动的自我进化
1. 损失函数:性能度量尺
l分类任务:交叉熵损失(Cross-Entropy)
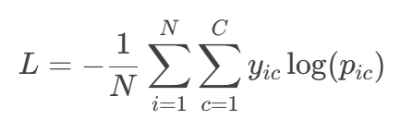
l回归任务:均方误差(MSE)
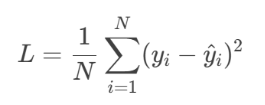
2. 反向传播:误差的逆向溯源
通过链式法则逐层计算梯度:
1.计算输出层误差
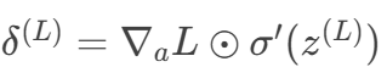
2.反向传播至隐藏层:
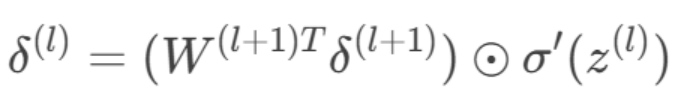
3.参数更新:
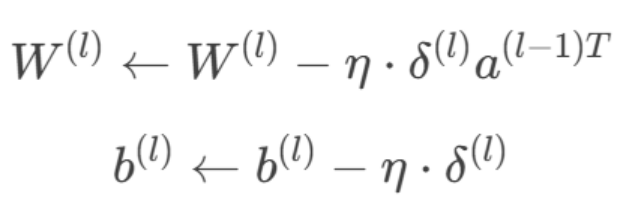
3. 优化器加速策略
动量(Momentum):引入历史梯度方向惯性
Adam:自适应学习率+ 动量二合一
五、优势与局限:初代AI的荣光与瓶颈
优势
✅普适性强:可建模复杂非线性关系
✅自动特征学习:无需人工设计特征
✅并行计算友好:矩阵运算契合GPU架构
局限
⛔参数量爆炸:全连接导致计算成本高(改进:卷积网络局部连接)
⛔忽略序列信息:无法处理时序数据(改进:循环神经网络)
⛔过拟合风险:需配合Dropout/L2正则化
六、实战应用:从理论到落地的经典场景
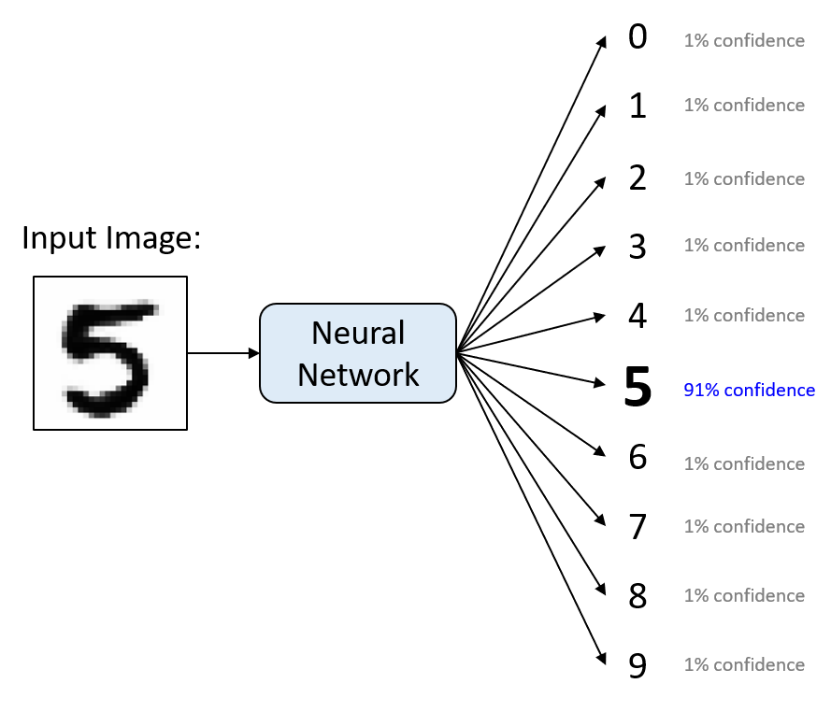
1. 手写数字识别(MNIST)
l网络结构:784-512-256-10
l准确率:约98%(基础基准任务)
2. 客户流失预测
l输入特征:消费频率、客单价、投诉次数等
l输出:流失概率(二分类)
3. 房价预测
l特征:面积、房龄、地理位置编码
l输出:连续型房价估值
4. 传感器异常检测
l输入:设备振动频谱特征
l输出:异常评分(回归)或故障类型(分类)
七、现代变体与进化方向
1. 深度前馈网络
l增加隐藏层数(如10层以上)
l配合残差连接(ResNet思想前身)
2. 自编码器(Autoencoder)
l前馈网络的特殊形态:编码器(降维)→解码器(重建)
l应用:数据去噪、特征提取
3. 前馈网络+注意力机制
l引入注意力权重动态调整特征重要性
l示例:Vision Transformer中的Patch处理
总结:前馈网络——AI世界的字母表
正如26个字母能组合出万千文字,前馈神经网络的基础结构衍生出卷积网络、Transformer等复杂架构。理解这个“智能字母表”,不仅让我们读懂深度学习的开篇章节,更为探索更浩瀚的AI宇宙提供了基本语法。
学习建议:
l使用TensorFlow Playground可视化工具观察网络运作
l从零实现MNIST分类(代码量行)
l对比不同激活函数/优化器的性能差异
前馈神经网络如同机械时代的蒸汽机——看似简单,却是开启智能革命的第一个火花。
找华算做计算👍专业靠谱省心又省时!
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
