

如果说监督学习是“手把手教学”,无监督学习是“自主探索”,那么强化学习(Reinforcement Learning, RL)则像一场刺激的生存游戏——机器作为智能体(Agent),在未知环境中通过试错、奖惩和自我调整,最终学会长期收益最大化的决策策略。从AlphaGo战胜人类棋手到机器人灵活行走,强化学习正在突破传统AI的边界。


一、核心思想:与环境的博弈中学习
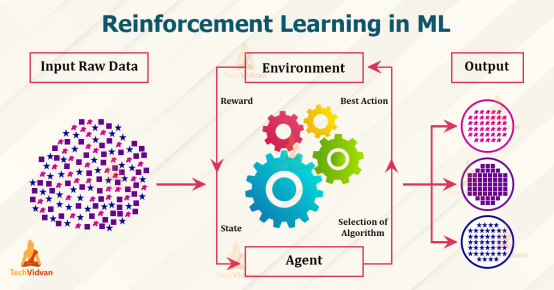
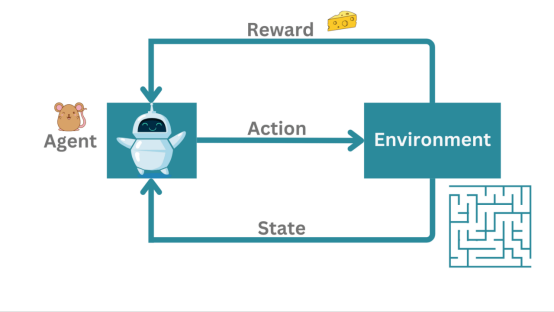
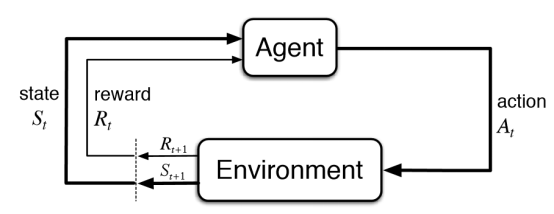
1. 定义与基本框架
强化学习是一种序列决策过程,核心要素包括:
智能体(Agent):学习主体(如游戏AI、自动驾驶系统)
环境(Environment):智能体交互的外部世界(如棋盘、道路)
状态(State):环境当前情况的描述(如棋局、车辆位置)
动作(Action):智能体可执行的操作(如移动棋子、刹车)
奖励(Reward):环境对动作的即时反馈(如得分增加、碰撞惩罚)
策略(Policy):从状态到动作的映射规则(智能体的“行为准则”)
-
目标:通过交互学习最优策略,最大化累积奖励(而非单步收益)。
2. 人类行为类比
婴儿学步:跌倒(负奖励)→调整姿势→成功行走(正奖励)
股票投资:买入/卖出(动作)→收益波动(奖励)→优化投资策略
游戏玩家:尝试不同战术→积累经验→成为高手
二、核心要素深度解析
1. 奖励设计:AI行为的指挥棒
稀疏奖励问题:关键动作可能延迟获得反馈(如围棋最终胜负)
解决方案:设计中间奖励(如占领棋盘区域得分)
奖励塑造(Reward Shaping):通过人工设计加速学习
例:教机器人走路时,除“到达终点”外,增加“保持平衡”奖励
2. 探索与利用的平衡
探索(Exploration):尝试新动作以发现更好策略
利用(Exploitation):执行已知最优动作以获取稳定收益
经典策略:
-ε-贪婪策略:以ε概率随机探索,否则选择最优动作
-汤普森采样:基于概率分布动态调整探索强度
3. 马尔可夫决策过程(MDP)
核心假设:下一状态仅依赖当前状态和动作(历史无关)
数学建模:
-状态转移概率:
-奖励函数:
-折扣因子:γ(权衡即时与未来奖励)
三、经典算法全景图
1. 基于值函数的方法
核心思想:学习状态或状态–动作对的价值(Q值),选择价值最高的动作。
-
Q-Learning:
更新公式:
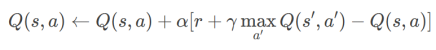
特点:离线学习(无需遵循当前策略)
案例:训练AI玩Flappy Bird,学习每个位置的最佳跳跃时机
-
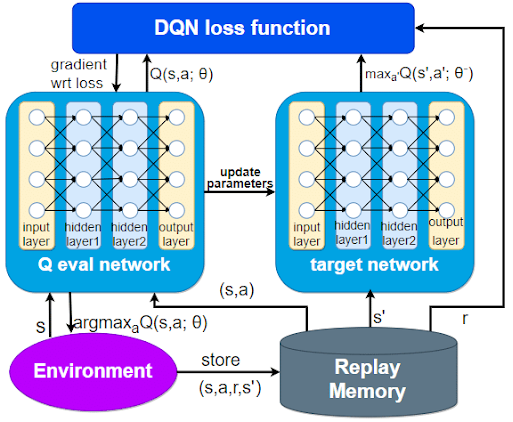
深度Q网络(DQN):
创新点:用神经网络逼近Q值函数,解决高维状态问题
关键技术:经验回放(打破数据相关性)、目标网络(稳定训练)
成就:Atari游戏超越人类水平
2. 基于策略梯度的方法
核心思想:直接优化策略函数,通过梯度上升增加高回报动作的概率。
-
REINFORCE算法:
策略更新:
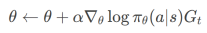
Gt:从时刻t开始的累积折扣奖励
应用:训练机器人完成复杂动作(如后空翻)
-
PPO(近端策略优化):
优势:通过限制策略更新幅度保持训练稳定性
应用:OpenAI Five在DOTA 2中击败职业选手
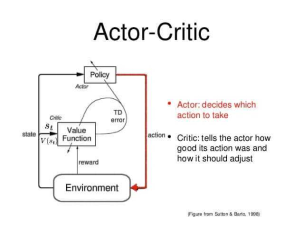
3. 演员–评论家架构(Actor-Critic)
-
融合思想:
演员(Actor):负责生成动作策略
评论家(Critic):评估状态价值并提供反馈
协同优化:像导演与影评人的关系
-
代表算法:
A3C(异步优势演员–评论家):多线程加速训练
SAC(柔性演员–评论家):兼顾探索与稳定性
四、强化学习的独特挑战
1. 样本效率低下
需大量交互数据(如机器人物理实验耗时耗能)
解决方案:
-仿真训练+迁移学习(如用虚拟环境预训练自动驾驶模型)
-模仿学习(向人类示范数据学习)
2. 稀疏奖励困境
关键奖励信号极少(如航天器成功着陆)
解决方案:
-分层强化学习(先学子任务,再组合)
-内在好奇心机制(鼓励探索新状态)
3. 安全性与伦理风险
探索过程可能导致危险动作(如自动驾驶测试事故)
解决方案:
-安全约束(限制动作空间)
-离线强化学习(仅从历史数据学习)
找华算做计算👍专业靠谱省心又省时!
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
