

决策树(Decision Tree)是一种模仿人类决策过程的机器学习算法,通过一系列“是非判断”将复杂问题层层拆解,最终得出预测结果。因其直观易懂、适用性广的特性,它被誉为“最像人脑”的算法,广泛应用于医疗诊断、金融风控、客户分群等领域。
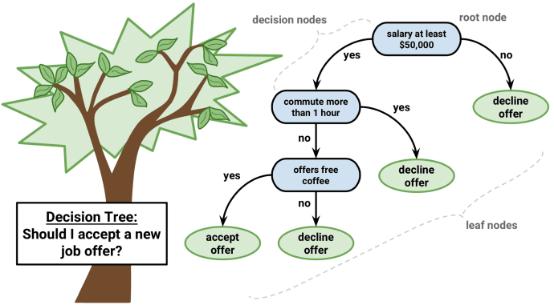

一、核心思想:分而治之的决策大师
1. 基本概念
-
树形结构:
根节点:起始问题(如“年龄>30岁吗?”)
内部节点:中间判断(如“收入>5万吗?”)
叶节点:最终结论(如“批准贷款”)
-
决策路径:从根节点到叶节点的一条判断链
示例:
年龄>30? → 是 → 收入>5万? → 否 → 拒绝贷款
2. 核心逻辑
-
递归分割:不断选择最佳特征将数据划分为更纯的子集
-
终止条件:
子集中样本全属同一类别
特征已用完,或树深度达到预设阈值
3. 人类决策类比
医生诊断:
患者发烧吗?→ 是 → 咳嗽吗? → 是 → 检测流感病毒 → 确诊流感
购物决策:
预算>1000元? → 否 → 需要便携吗? → 是 → 选择轻薄本
二、决策树如何选择“最佳分裂点”?
1. 纯度衡量指标
决策树的优化目标是让子节点的数据尽可能“纯粹”(同类样本聚集)。常用指标:
(1)信息增益(Information Gain)
-
基础概念:使用信息熵(Entropy)衡量数据混乱度
-
熵公式:
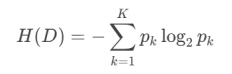
Pk:数据集中第k类样本的比例
熵值范围:0(完全纯净)到1(最大混乱,二分类时)
-
信息增益计算:
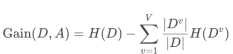
A:某个特征
V:该特征的取值数(如“性别”有2个取值)
选择准则:信息增益越大,特征越优先分裂
示例:
原始数据集熵为1(二分类各占50%)
按某特征分裂后,两子集熵分别为0和0.5
信息增益= 1 – (0.5×0 + 0.5×0.5) = 0.75
(2)基尼不纯度(Gini Impurity)
-
公式:

特点:计算速度比熵更快,结果相似
CART算法默认使用基尼系数
2. 分类 vs 回归
-
分类树:叶节点输出类别标签(如“是否逾期”)
-
回归树:叶节点输出连续值(如“房价=120万元”)
分裂准则改用均方误差(MSE)或平均绝对误差(MAE)
三、决策树的构建步骤
1. 数据准备
处理缺失值:填充或分配至多数类
离散化连续特征:如将年龄分为“青年/中年/老年”
2. 生成树流程
1)从根节点开始,计算所有特征的分裂指标(信息增益/基尼系数)
2)选择最优特征作为当前节点的分裂条件
3)按特征取值划分子节点
4)对每个子节点递归重复上述过程,直到满足终止条件

3. 剪枝处理
为防止过拟合(模型过度记忆训练数据细节),需对树进行剪枝:
预剪枝:提前停止分裂(如限制树深度、设置最小样本数)
后剪枝:生成完整树后,自底向上合并冗余节点
四、决策树家族:三大经典算法

关键改进:
C4.5:引入信息增益率(解决信息增益偏向多取值特征的问题)
CART:二叉树结构(每个节点仅分裂为两个子节点)

五、决策树的优势与局限
优势
✅解释性强:决策路径可翻译成自然语言规则
✅兼容多类型数据:可处理数值、类别、缺失值
✅无需复杂预处理:不受特征量纲影响,对异常值不敏感
局限性
⛔容易过拟合:不加控制可能生成复杂树(需依赖剪枝)
⛔稳定性差:数据微小变化可能导致树结构剧变
⛔次优决策:贪心算法无法保证全局最优
找华算做计算👍专业靠谱省心又省时!
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
