同步辐射X射线吸收精细结构(XAFS)数据分析的预处理是确保数据准确性和可靠性的关键步骤,主要包括能量校正、归一化和背景扣除。
许多人在处理XAFS数据时,仅停留在知其然的层面。不知道为何要进行这些操作呢?该怎么进行处理?对数据有什么影响呢?本期将针对这些问题进行深入探讨。主要从以下七大部分进行介绍。
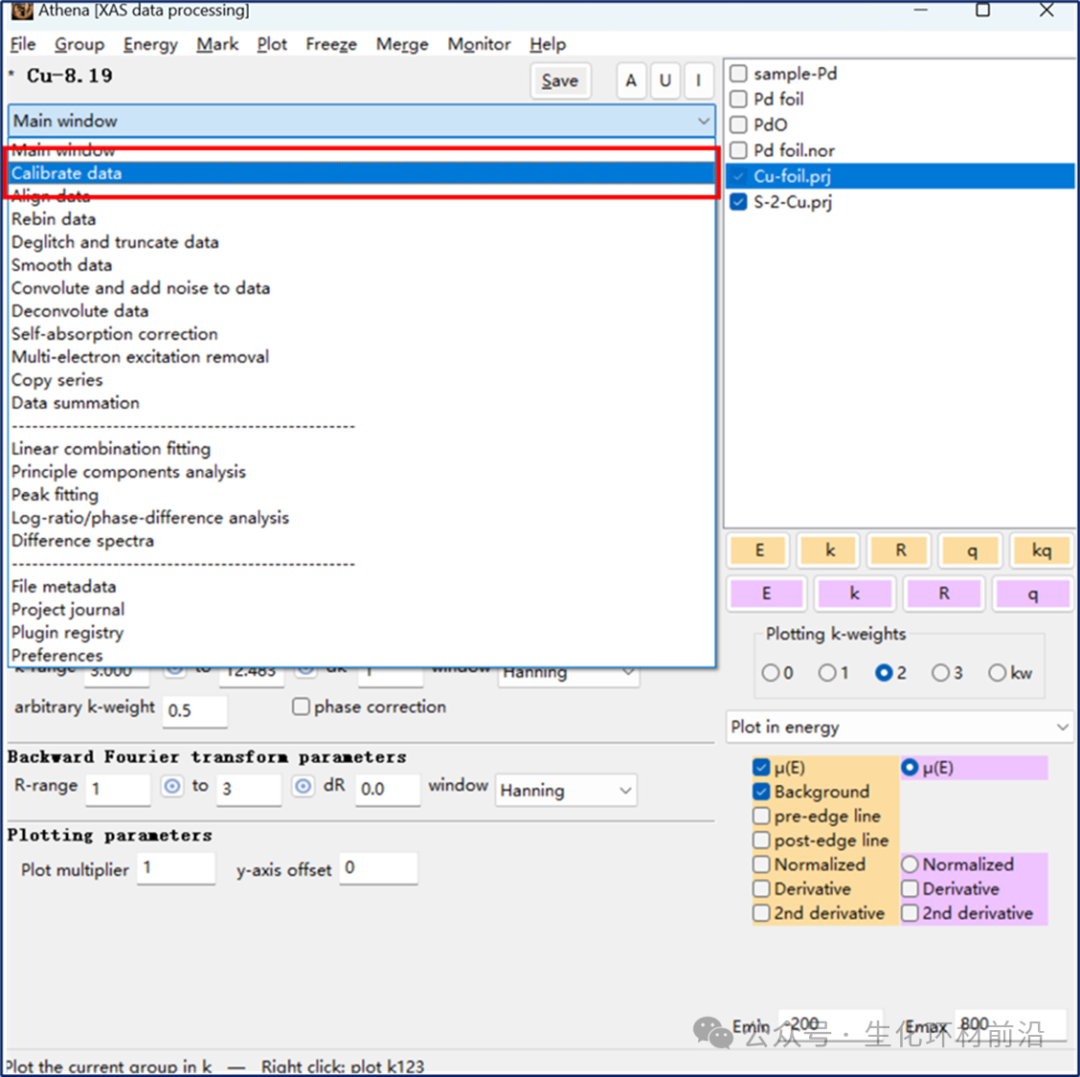
由于在采集不同批次的样品时会有能量偏移,这种问题即便在同步辐射装置中也不可避免,因此需要进行人为校准。一般是基于测得的Foil样品进行矫正。
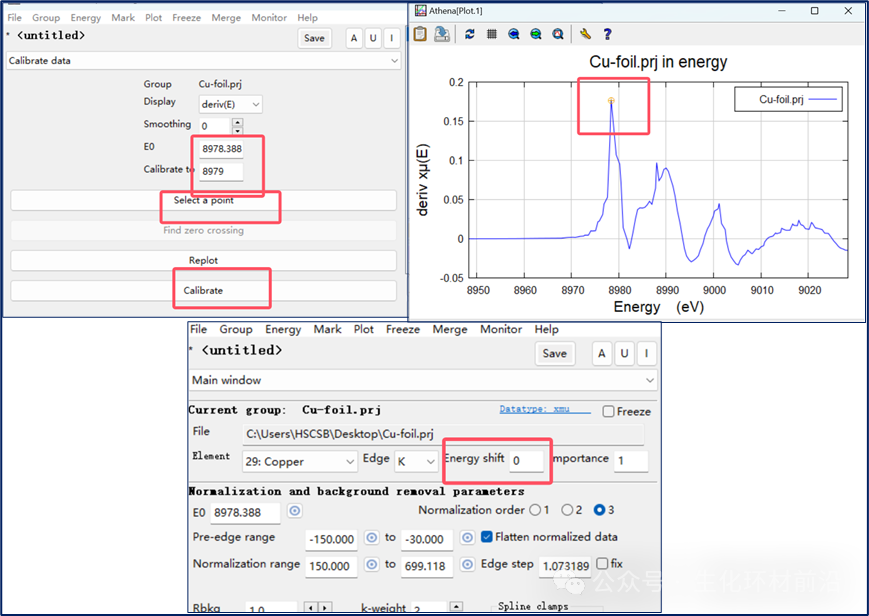
E0的确定:默认情况下,Athena让IFEFFIT算法确定E0。IFEFFIT的算法是找到μ(E) 的一阶导数的第一个峰值。
IFEFFIT算法确定E0:为了避免在有噪音的边前中选错某个点,IFEFFIT会经过算法多重验证E0是否位于 μ(E) 导数中能量先增后减的点。
E0的用途:它可以确定 Z和edge参数,是归一化、边前和样条范围参数的能量参考,是AUTOBK算法中的边缘能量 。
E0的优化:Calibrate data和Align data工具可用于校准 E0。也可以直接在主菜单栏下,Energy shift对应的文本框中输入数值。
图1.2 手动输入E0
特殊情况:在某些情况下,默认算法会失效。如,噪音较大的数据可能会导致 E0识别错误;有两个拐点的边也可能会导致选择错误的E0;具有明显边前峰的材料(例如 K2CrO4或Na2CrO4)也会导致E0误判。
注意:不同批次的样品的Energy shift都要和其同批次测试的标样一致,校准之后不同批次测试的数据也可以放一起比较了;在样品的Energy shift设定后,一定要进行E0的选择,否则会影响后续的k空间和R空间。
除了上面描述的默认方法之外,Athena 还提供了一些其他算法来设置E0:
原子值列表:将使用零价元素边缘能量的列表值。要确定元素,将使用IFEFFIT找到E0的临时值。一旦找到Z和 Edge,E0将被确定。
边步长:在该算法中,将使用IFEFFIT找到E0的临时值。对数据进行归一化,并选择边的高度等于边步长指定分数的点作为E0。该归一化最多迭代5 次。分数的值由Bkg→fraction首选项设置,默认值为0.5。
零交叉:同样,使用IFEFFIT可以找到E0的临时值。计算 μ(E) 的二阶导数,然后 Athena在能量的两个方向上搜索二阶导数的最近零交叉点,将其定为E0。
L边白线峰:使用IFEFFIT可以找到E0的临时值。找到白线的峰值,即E0初始值之后μ(E)的一阶导数的零交叉点,并将其用作E0。
由于所有这些附加算法都依赖于IFEFFIT对E0的初始猜测,因此每个算法都受到默认算法的相同影响。
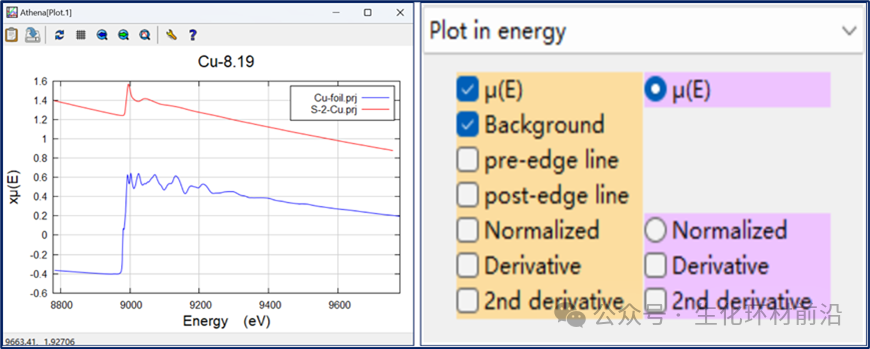
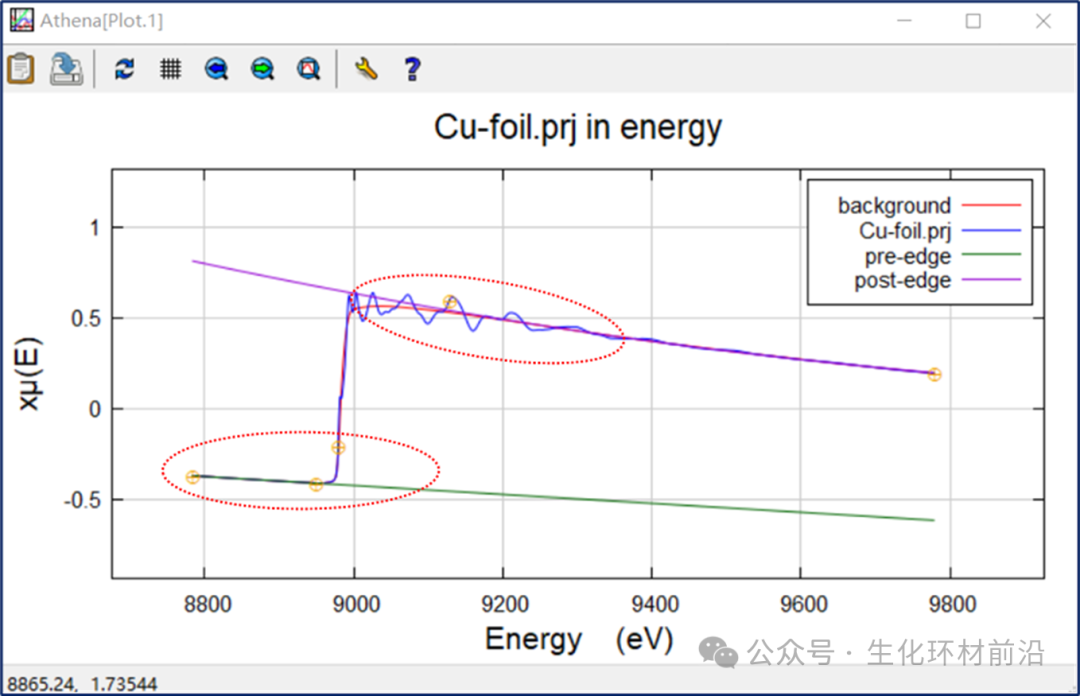
XAFS数据本质上描述了样品对X射线吸收系数与能量之间的关联。这种吸收系数不仅受能量的影响,还与样品的厚度、测试条件(例如光通量)、样品制备、吸收剂浓度、检测器和放大器设置等因素密切相关。因此,直接比较两组样品的XAFS数据是不合理的,如图2.1所示,原始的μ(E)曲线在噪音和信号强度上存在显著差异,直接比较会使得数据不精确。
图2.1 Cu系样品测得的XASF数据没有进行归一化
为了解决这一问题,我们采用归一化处理,即对样品的边前进行扣除,调整边前后的吸收变化,使其比值标准化为1。这种处理方式是为了消除不同样品间由于厚度和测试条件差异带来的影响,从而使数据比较更为准确和直观。
多数情况下,对于测量的μ(E)光谱,Athena可以使用其默认参数很好地对数据进行标准化并去除背景。但在特殊情况下(噪音、带有白线峰的数据、测试中突然终止于扩展边的数据),需要人为干预。前提是,要充分了解主窗口中各种参数如何影响数据。
对于归一化过程选择由FEFF计算的μ(E)和χ(k)光谱的比例来与归一化数据进行比较。
∵ μ(E) = μ0(E)*(1 + χ(E))
∴ χ(E) = (μ(E)- μ0(E))/ μ0 (E)
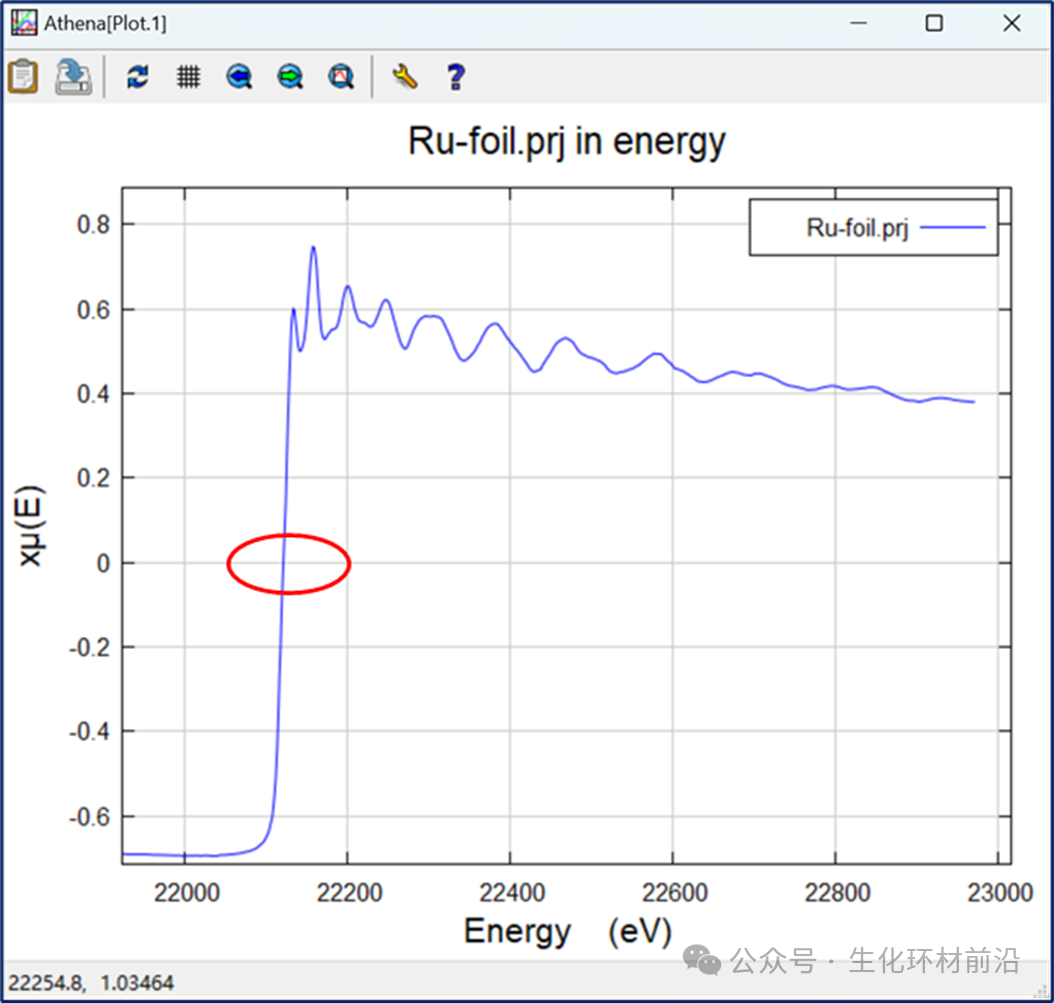
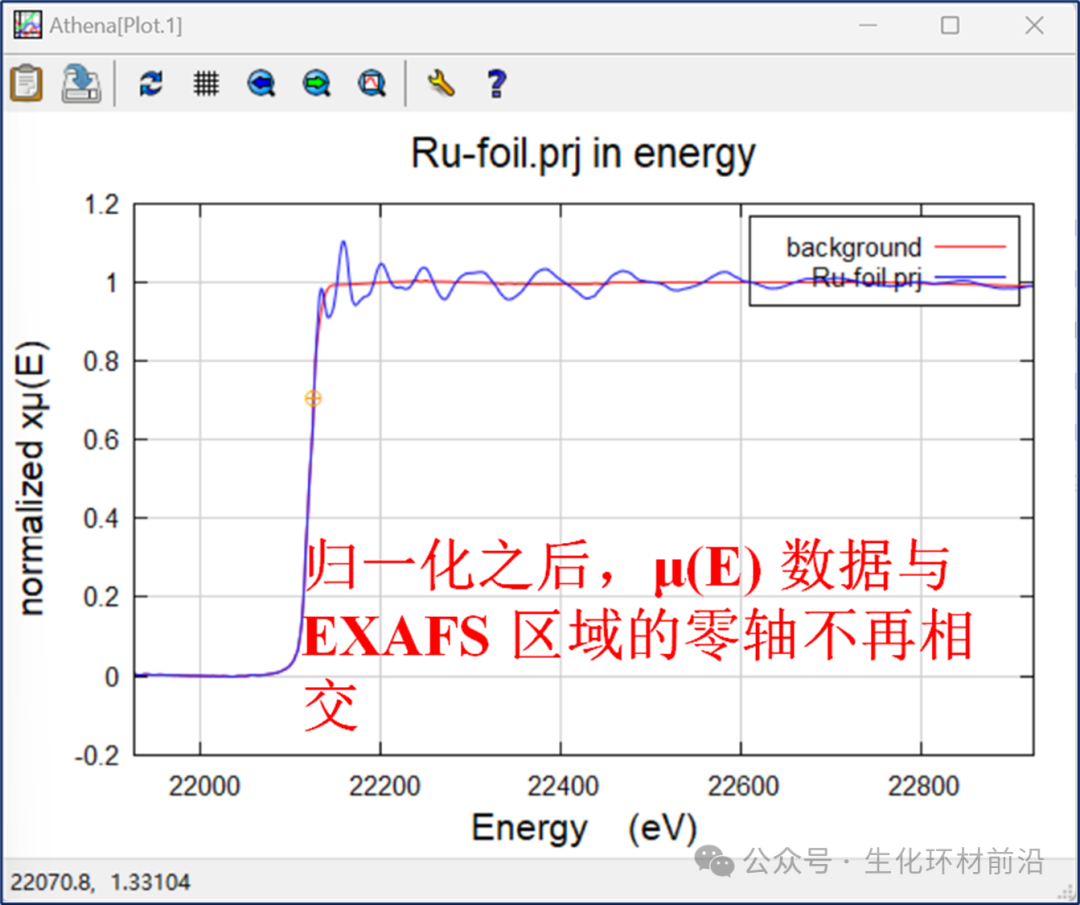
这个方程并不是通常用来从测试光谱中提取χ(k)的方程。原因在于方程的分母包含了一个因子μ0(E)。在实际情况下,μ0(E)不可能永远大于0或者小于0,它也可能等于0。当μ0(E)等于0时,这会导致方程出现除以零的情况,这是数学上不允许的。如下图所示,对于Ru光谱,探测器的设置使得μ0(E)数据与EXAFS的零轴相交。
图2.2归一化前,Ru的μ0(E)数据与 EXAFS 区域的零轴相交
为了解决这个问题,通常避免函数归一化,而是进行吸收边归一化:
χ(E)=(μ(E)- μ0(E))/μ0(E0)
其中,μ0(E0)是在吸收边处求得的背景函数值。这虽然解决了μ0(E)函数为0的问题,但又引入了另一个问题。由于真正的μ0(E)函数应该具有某种能量依赖性,因此用μ0(E0)进行归一化会将衰减引入χ(k),该衰减与能量大致呈线性关系。因此,吸收边归一化会在χ(k) 数据中引入一个人为的误差σ2项,σ2项相对于前者产生的误差小得多。
图2.3归一化后,Ru的μ(E)数据与 EXAFS 区域的零轴不再相交
由上述描述得知,XAFS图谱的归一化由E0、边前范围和归一化范围参数的值决定。
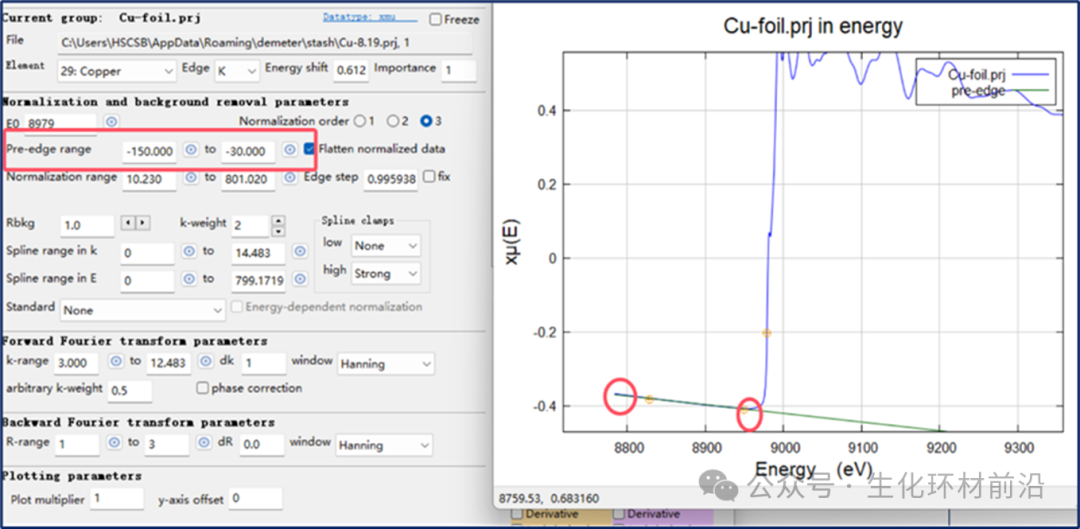
判断边前线和边后线带有一定的主观色彩。可以使用归一化控件和背景去除按钮中的per-edge range和Normalized range对数据进行选点进行归一化。绘制边前线和边后线时,per-edge range和Normalized range参数的位置由小橙色标记显示。从下图可以看出,Cu foil数据的参数选择得很好,因为该图中的两条线在各自的范围内均穿过数据的中间。
图2.5带有边前线和边后线的Cu foil μ(E)
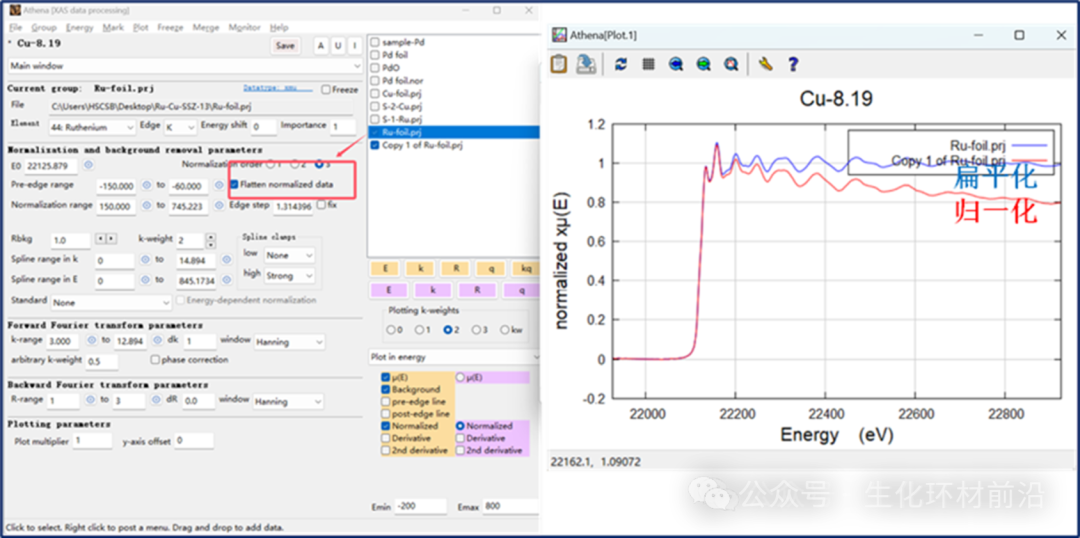
在处理XANES数据时,Athena软件还扁平化算法来更好地分析和展示结果。在下图中,显示了扁平化数据以及已关闭扁平化数据副本。
图2.6使用Ru foil比较标准化(蓝色)和平坦化(红色)数据
为了展现数据的扁平化效果,我们通常需要在E0点之后从数据中扣除边前后的斜率和积分差。这样做可以将数据的振荡部分调整至y=1的水平线。因此,经过扁平化处理的μ(E)数据范围将从0延伸至1。这种处理方式主要是为了更直观地展示数据,并不会影响到从μ(E)光谱中提取χ(k)的过程。
采用这种展示XANES数据的方法能够消除后边缘区域形状的诸多差异。在进行差谱计算、自吸收校正、线性组合拟合或分峰拟合等操作时,使用扁平化数据往往比简单的标准化数据更为有效。
边前结构的开始范围也应设置为端点处,整体边要与pre-edge这条线尽可能重合。
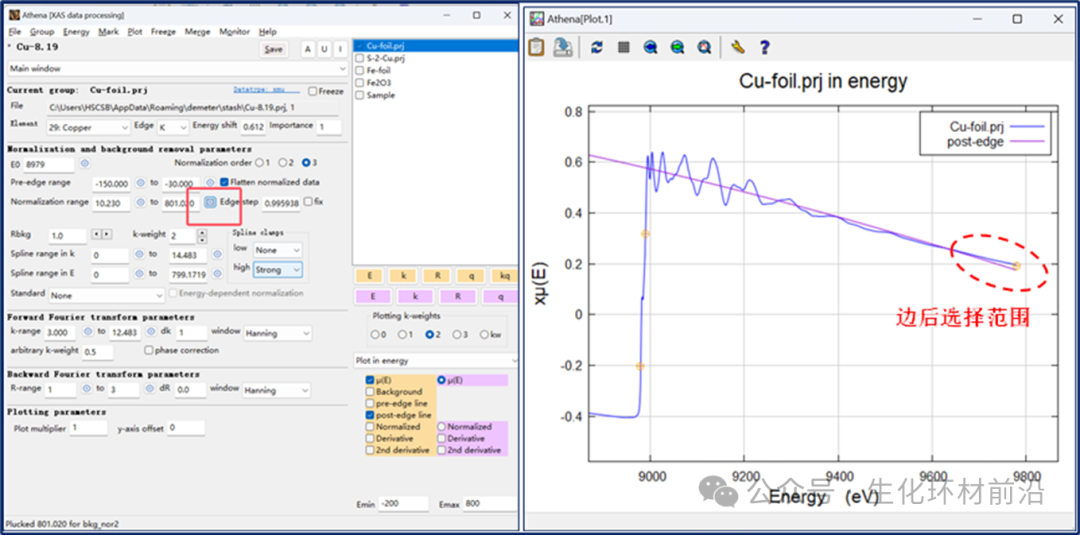
在许多情况下,标准化参数选择中的细微错误可能会影响XANES数据的解释方式以及χ(k)数据的归一化方式。一般情况下会将边后的最大范围选择在端点处。
上一节讨论的背景范围由Rbkg参数决定。这是主窗口背景消除部分显示的第二个参数。当数据被导入Athena时,Rbkg被设置为其默认值,通常为1。
图3.1默认背景函数下μ0(E),χ(k)及χ(R)数据
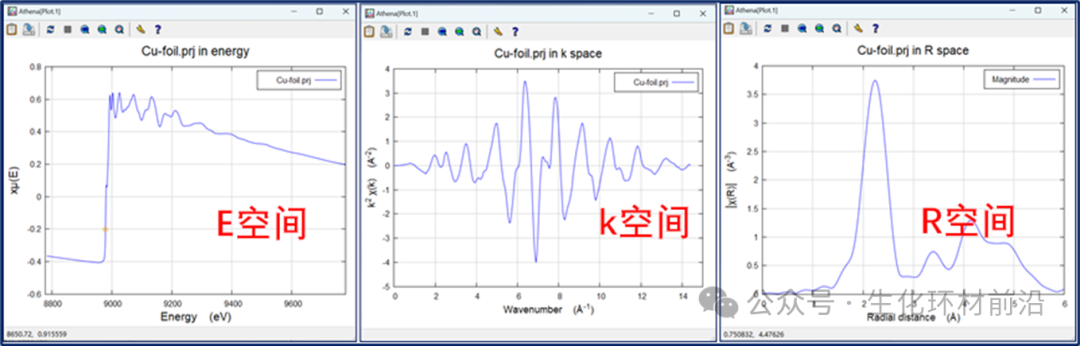
从数据中减去背景函数并进行归一化,得到μ0(E)函数。按下k按钮查看χ(k),按下R按钮时,就会经过傅里叶变换得到χ(k),如上图所示。
因此,Rbkg是AUTOBK算法删除傅里叶分量的数值。小于1时χ(R)函数本质上为0,大于1时频谱不为零。
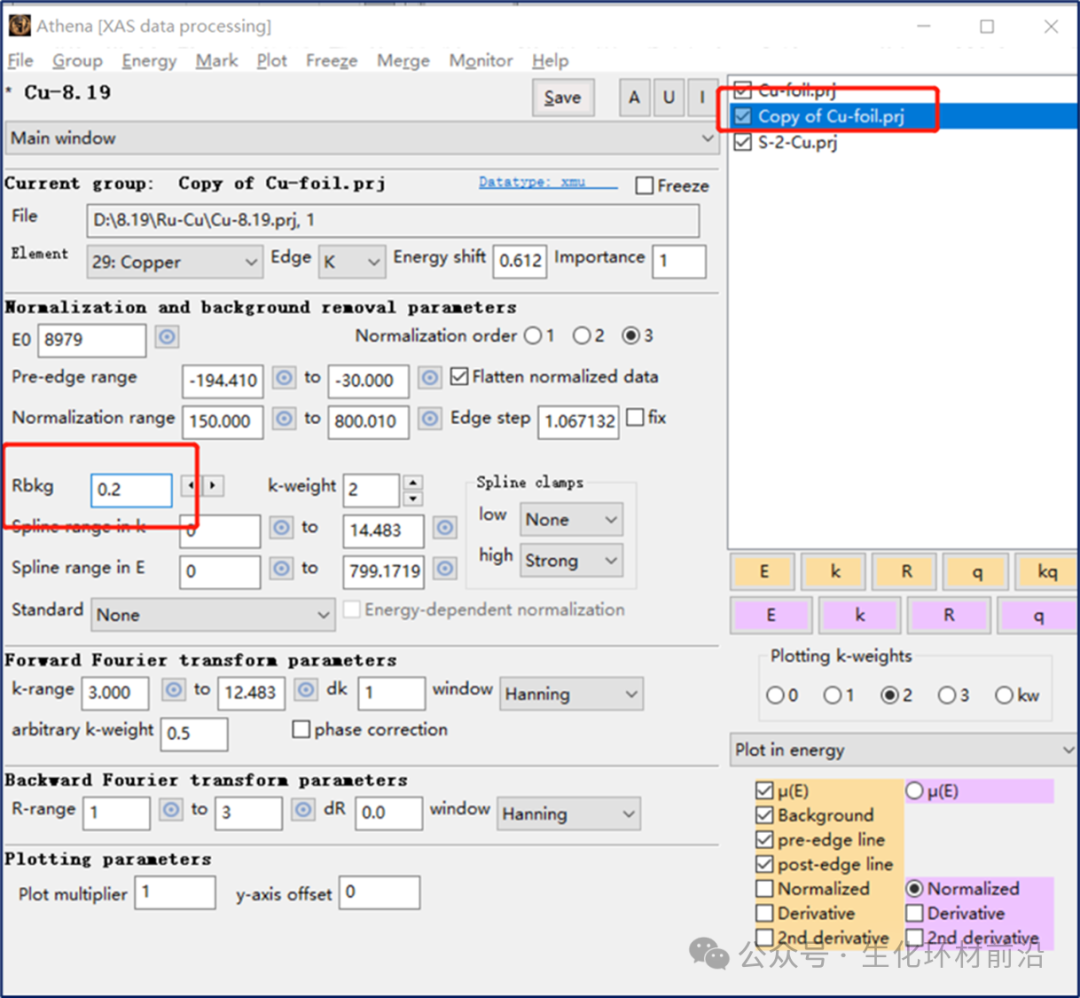
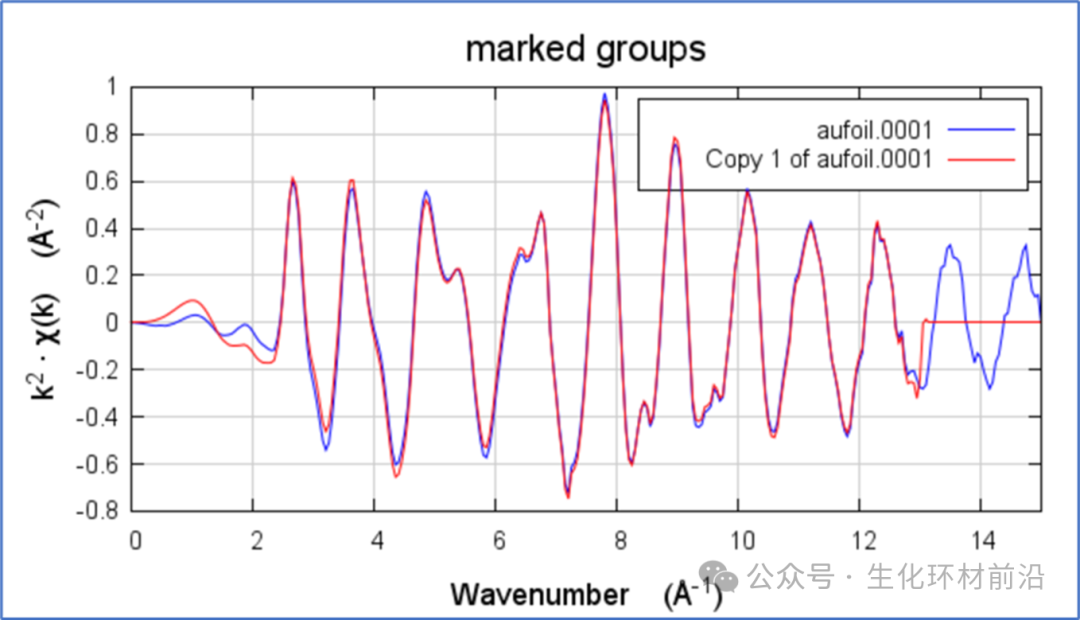
那么Rbkg选择不同的值会产生什么效果?可以复制一份数据,以便进行比较不同的值。选择要复制的数据,点击右键,Copy current group即可。
单击组Copy of Cu foil以在主窗口中显示其参数。将Rbkg更改为0.2。现在我们要直接比较这两种去除背景的方法。单击数据旁边的小复选按钮,可以绘制μ0(E),χ(k)及χ(R)谱图。如下图所示。
图3.3 Rbkg值分别为1和0.2时数据和其副本的μ0(E),χ(k)及χ(R)的数据
蓝色光谱与所期望的EXAFS数据类似,而红色光谱相差甚远。这不难解释,事实上,Rbkg参数指定R值,低于该值时,数据将从μ(E)光谱中删除。对于红色光谱,低于0.2时信号非常小,而第一个大峰实际上高于0.2。
这两个图形绘制为χ(k),如中上方所示。蓝色光谱围绕零轴振荡。红色光谱具有明显的长波长振荡。正是这种振荡导致了χ(R)光谱中有低R峰。使用0.2的Rbkg值会产生无法遵循数据实际形状的背景函数。
如果将Rbkg的值设置为非常大的值,又会发生什么情况?这里显示了值1和2.5的μ0(E),χ(k)及χ(R)数据。
图3.4 Rbkg值分别为1和2.5时数据和其副本的μ0(E),χ(k)及χ(R)的数据
使用非常大的Rbkg值会导致χ(R)中的第一个峰值发生显著变化。我们可以通过查看能量中的背景函数来了解原因。使用较大的Rbkg值,背景函数有足够的自由度以与数据相似的频率振荡。这导致第一个峰值的强度降低。
用于计算背景函数的样条函数具有有限的振荡自由度。样条函数节点的数量由Nyquist方程确定。该数字与k空间中数据的范围乘以Rbkg成正比。这些节点在波数中均匀分布。因此样条函数只能具有低于Rbkg分量。
一般而言,我们希望将Rbkg设置得尽可能大,以便尽可能抑制低R峰值。另一方面,过大的值将导致数据损坏。这就需要一定的经验了。Rbkg一般是临近原子距离的一半左右。但这只是一个经验法则。在实际应用中,如遇到噪音数据、存在强烈白线峰的数据,或是被其他吸收边截断的数据,就需要更加细致地考量Rbkg的设置。
XANES谱图是叠加在正常吸收边上的。进行背景去除是为了提高数据的质量和可解释性。背景信号,包括非精细结构吸收和仪器噪声,可能会掩盖重要的精细结构特征,增加数据的复杂性,并影响定量分析的准确性。通过背景去除,可以清晰地观察到样品的局部结构特征,如原子配位环境和键长信息,从而提高模型拟合的质量,减少误差,并使数据标准化,便于不同样品或实验条件下的数据比较。
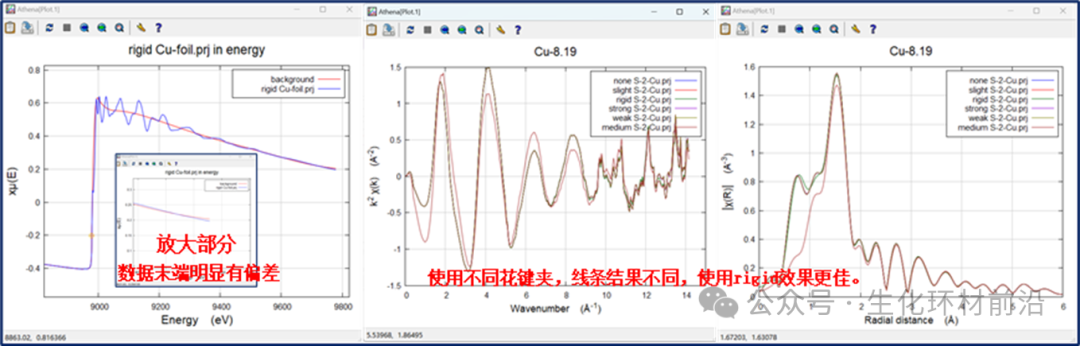
使用分段样条函数来近似背景函数的缺点之一,是由于没有更多数据在边前或边后,样条函数的端点有些模糊。有时,这会导致样条函数的端点向上或向下倾斜,远离μ(E)数据。这会导致χ(k)数据严重失真。
IFEFFIT提供了一种称为样条线夹工具。样条和数据之间的差异是针对前后五个数据点计算的。将计算出的能量差异总和乘以用户选择的比例因子,并添加到从低于Rbkg的R范围计算出的χ2中。这具有将样条夹紧到数据范围末端的效果。换句话说,利用先前的知识,即μ0(E)是通过μ(E)振荡结构的平滑函数,来对用于确定μ0(E)的拟合进行限制。
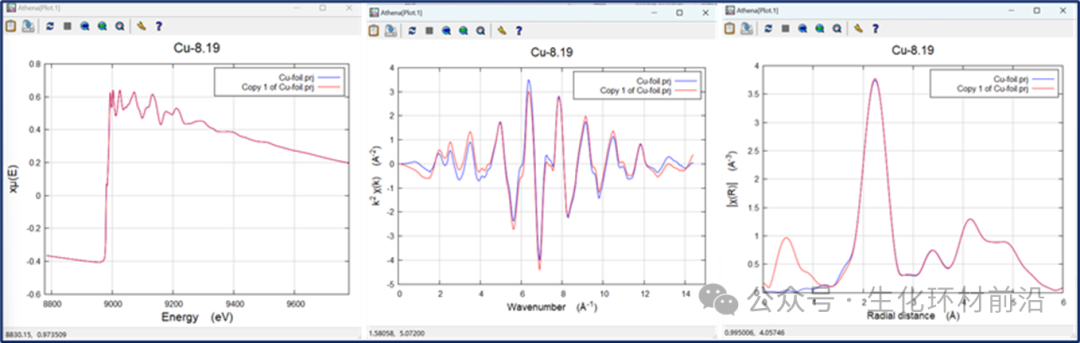
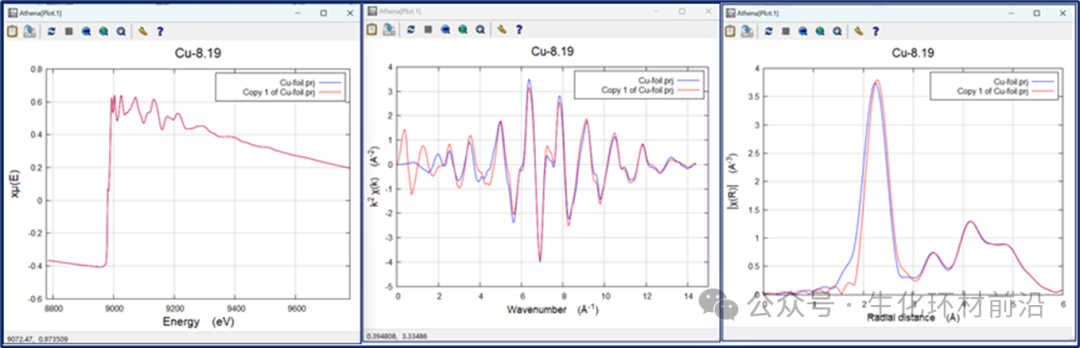
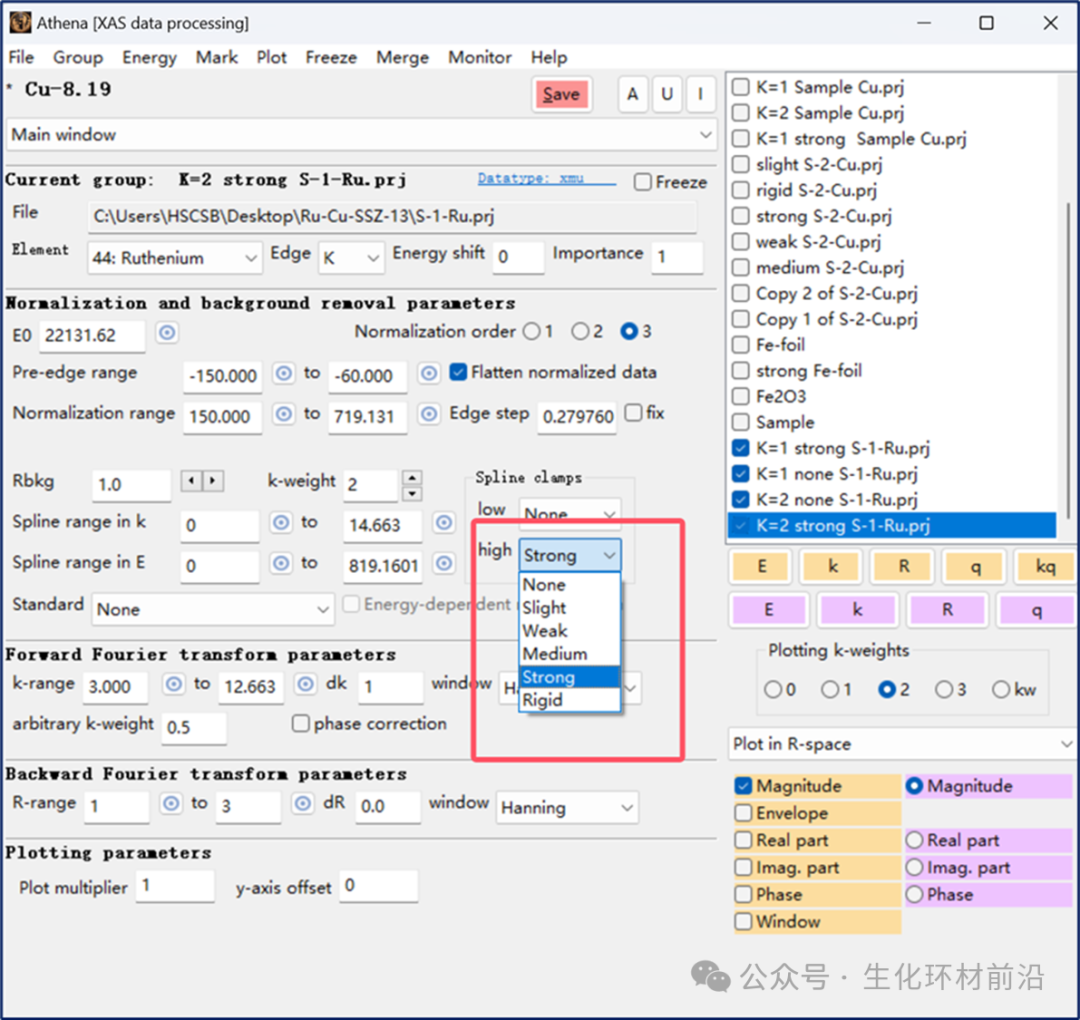
可选择的样条线夹的强度系数有:none、slight、weak、medium、strong或rigid。这些值的值为0、3、6、12、24和96,用于在χ2的评估中设置夹紧的强度。
图4.2 Cu foil数据,无减去背景,使用kweight=1和不同样条线夹的μ0(E),χ(k)及χ(R)数据
在较低能量处,样条线夹强度默认值为无,而在较高能量处,样条线夹强度默认值为强。样条线夹强度往往对数据的低能量端没有帮助。由于μ(E)数据在边缘附近变化较快,对于提高χ(k)数据的质量作用并不明显。在高能量处,强样条线夹通常会改善样条曲线在数据末端附近的行为。
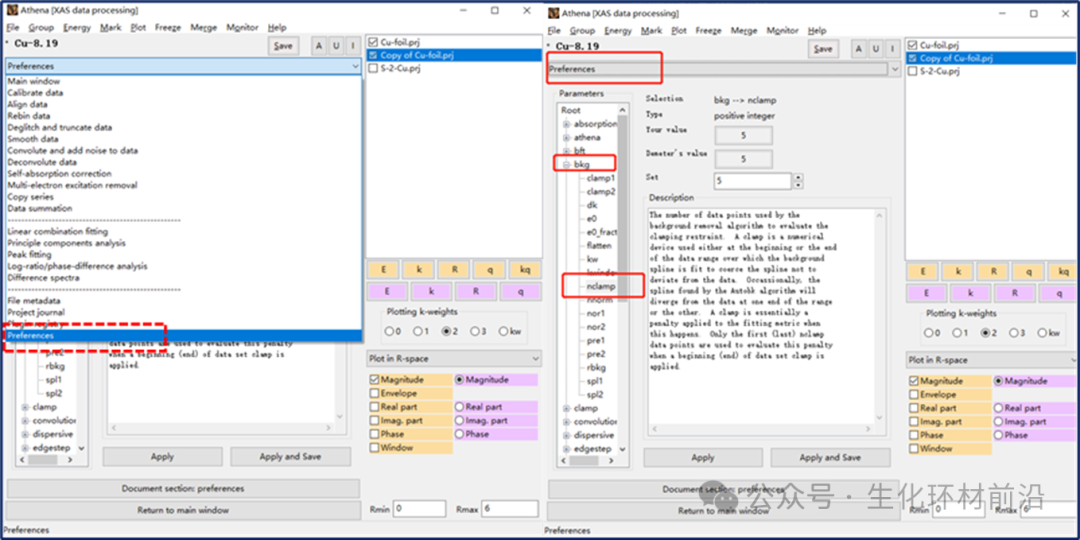
可以使用preference工具设置样条线夹。具体地,首先通过选择Bkg→nclamp首选项来改变数据范围的结束时间。Bkg→clamp1和Bkg→clamp2参数设置两个夹具的强度。优势可以通过更改数值来微调clamps。参数clamp→weak设置弱clamp值,依此类推。
kweight参数在这里的作用是加权傅立叶变换中的不同部分。通过调整kweight的值,可以强调数据的某些频率成分,这有助于在去除背景时保留更多的有用信息。例如,如果数据中存在高能量的振荡结构,增加kweight的值可能会帮助更好地保留这些结构。
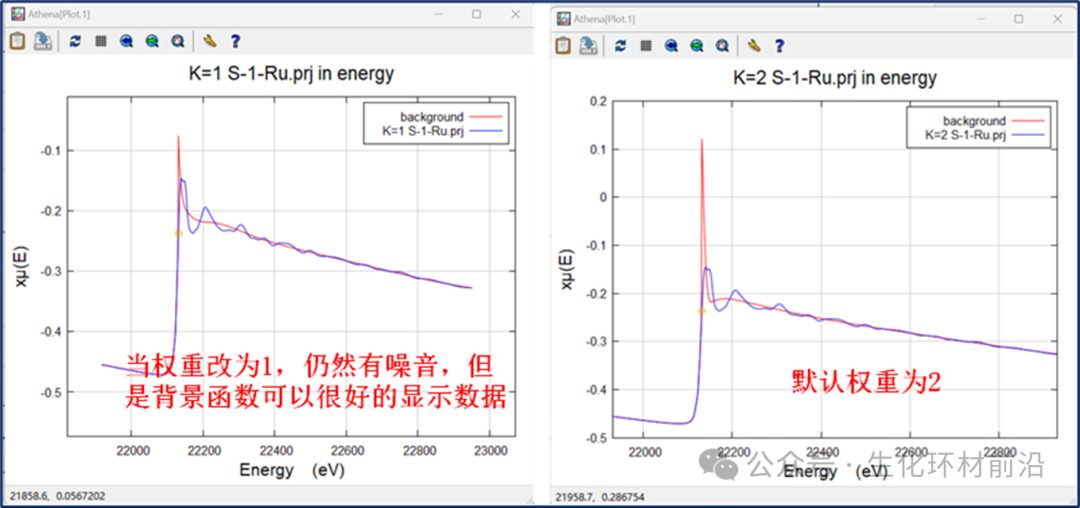
然而,如果数据中噪音较多,增加kweight的值可能会导致噪声被放大,从而影响背景去除的效果,使得最终的μ0(E)评估结果不准确,甚至会出现剧烈的振荡,如下例所示。
图4.4 当kweight为1、2时的μ0(E)数据
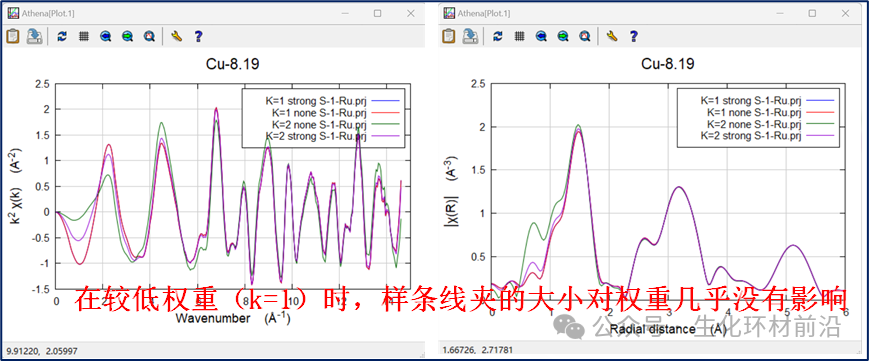
样条线夹和kweight参数有时会产生强烈的相互作用。样条线夹强的μ0(E)数据可能会对噪音大、k权重大的数据产生影响。降低样条线夹的强度有时会有所帮助。
图4.5 在较低权重时样条线夹的大小对权重几乎没有影响
在处理数据时,有时,较小的kweight与较强的样条线夹能够更好地展示数据。有时较大的kweight和较弱的样条线夹可能会提供更优的结果。还有情况是,较大的kweight和较强的样条线夹组合能够达到最佳效果。虽然不存在固定的规则来决定这些参数的最佳值,但通过实践和经验积累,可以培养出对不同数据类型应如何调整这些参数以达到最佳拟合效果的直觉。
当数据在高k值区域的信号非常微弱时,k加权可能会导致χ(k)数据的水平部分显著高于χ(k)数据的实际值。这种情况下,通过调整样条曲线的上限,可以更准确地反映数据的真实背景。
如果样本的不均匀性或其他测量问题导致背景函数的形状出现不稳定,调整样条曲线的上限可以帮助稳定背景函数的形状,从而提高背景去除的准确性。
调整样条曲线范围的下限或上限应基于数据特性。例如,如果数据中存在较强且尖锐的白线峰,AUTOBK算法可能难以准确跟踪μ(E)中快速变化的部分。在这种情况下,通过提高样条曲线范围的下限,可以有助于改善背景去除的效果。
图5.1改变样条范围后Au foil 的χ(k) 数据
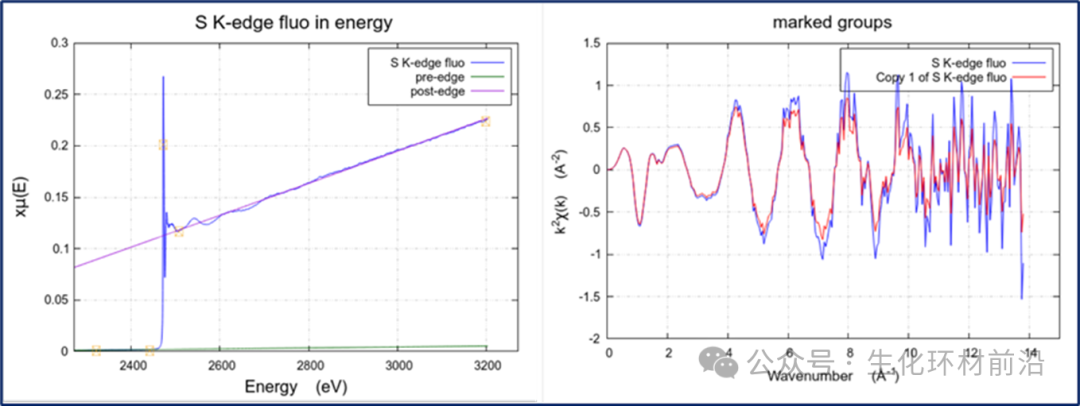
在低能量区域测量荧光数据时,可能会发现数据的整体形状与预期不同,如图中的S K边数据展示的那样。这种异常形状主要是由于荧光信号的能量依赖性,特别是与充满气体的I0室(即入射光束强度)有关。
随着入射光束能量的增加,I0室中气体的吸收率降低,根据荧光信号If /I0,导致荧光信号的μ(E)值随着能量的增加而增大。在进行吸收边归一化时,由于I0的能量依赖性,χ(k)信号可能会在能量增加时出现轻微的放大。
图 6.1荧光测得的S K 边光谱
为了校正由于I0能量依赖性导致的χ(k)信号放大效应,可以采用能量依赖性归一化方法。这种方法通过计算边前和边后线之间的差异函数来实现。只要这两条线表现良好,差异函数就是正定的。在进行背景去除之前,将这个正定的差异函数乘以μ(E),即能量依赖性函数,以此来校正χ(k)信号。
校正后的χ(k)信号,如图表中右侧的红色曲线所示,虽然校正量可能很小,但这种校正对于提高EXAFS分析的准确性是有帮助的。
注意:这种校正仅适用于荧光测量的低能 EXAFS 数据。此外,选择不当的边前边后线一起使用也会损坏数据。
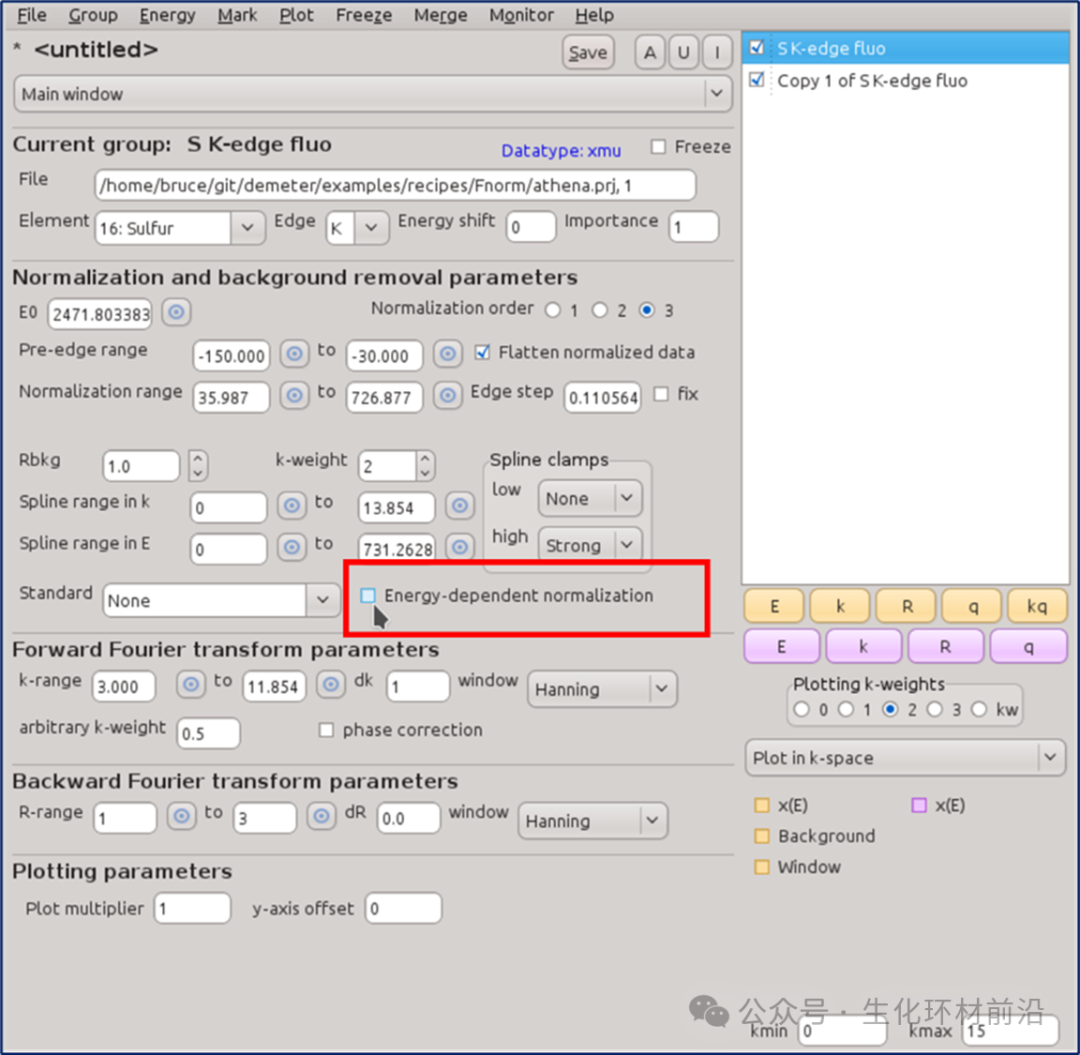
此能量依赖标准化的选项是控件背景去除部分底部附近的复选按钮,如下图所示。
图 6.2荧光测量的 S K 边 EXAFS 数据,已启用用于打开能量相关归一化的控件
此控件通常处于禁用状态。可通过Athena→show_funnorm 配置参数打开。如果导入的项目文件包含一个或多个使用能量相关标准化的组,则该控件将自动打开。
注意:在使用Athena软件进行EXAFS分析时,能量图显示的是未校正的μ(E)数据,而χ(k)、χ(R)和χ(q)数据则基于校正后的μ(E)。如果数据噪声大,能量图和χ(k)图的背景去除效果可能不一致。因此,即使能量图看起来没问题,χ(k)图的数据也可能不理想,反之亦然。使用此功能时请特别注意,并确保理解数据。因此,在使用Athena的这一功能时,需要谨慎并具备一定的预判能力。
在测量 XANES 数据时,有些学者可能只需要部分数据,所以试图将测量范围严格限制在吸收边附近的一个较窄范围内。例如,图7.1中红色轨迹的短跨度包括边缘中的三个小峰,这些小峰明确表明该物种为 Pd。那么,仅测量该短数据范围是否就足够了?
图7.1 Pd的数据被截断到边缘周围的区域
从某种意义上说,这是没问题的。如果测量的整个目的是为了进行指纹识别——这个样品是Pd还是其他样品?——那么在非常短的能量下测量的数据就足够了。然而,XANES 数据除了指纹识别之外还有很多用途。
对 XANES 数据的定量分析,例如线性组合拟合或主成分分析,都要求以合理、可重复的方式对数据进行标准化。如果谱图的数据范围不够宽,则很难很好地归一化 XANES 数据。
在进行EXAFS分析时,确保数据的完整性至关重要。如果数据在边后的第一个大振荡处被截断,将难以确定边缘后线的正确走向,从而影响边缘步长的准确判断。这可能导致归一化参数出现显著的系统不确定性,进而影响定量分析的准确性。
同样,前边缘区域的数据量也需充足,以确保前边缘线的正确处理。良好的实验实践是在边缘前后测量足够多的数据。对于XANES研究,建议在边缘前至少测量100 eV,在边缘后至少测量300 eV。如果测试时间有限,可以在边缘区域外稀疏测量,应至少在边缘后区域获取10个数据点,以确保标准化的可靠性。
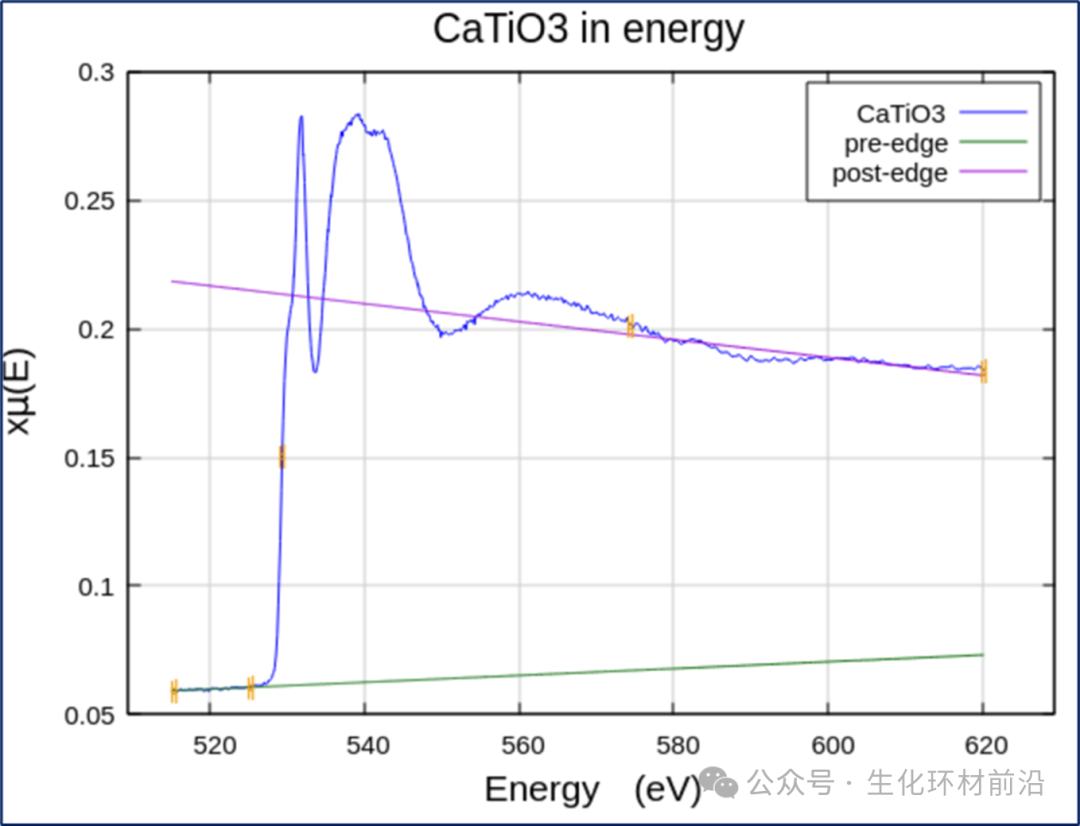
注意:数据范围的建议会根据具体情况而变化。例如,在CaTiO3的O K边数据中,即使数据仅延伸到边缘以上约90 eV,也可以进行合理的归一化。
图 7.2在软 X 射线光束线测量的CaTiO3的O K 边数据
在某些情况下,MBACK 算法可能有助于以合理的方式归一化短程数据。但对于如此短的数据范围也不是完全稳定的。MBACK在Larch中实现,但目前在Athena中不可用。
【高端测试,找华算】🏅同步辐射 全球机时,三代光源,随寄随测!最快一周出结果,保证数据质量!


声明:如需转载请注明出处(华算科技旗下资讯学习网站-学术资讯),并附有原文链接,谢谢!