

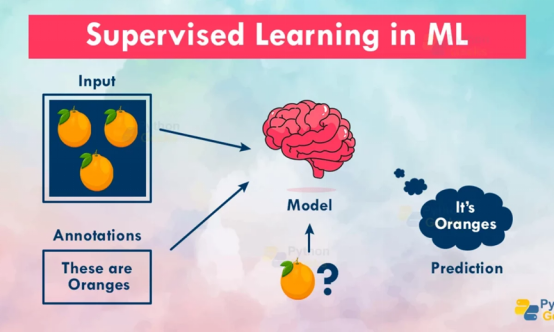
如果把机器学习比作学生,监督学习(Supervised Learning)就像一位严格的家教——它会先给机器提供大量带有标准答案的习题(训练数据),让机器通过反复练习总结规律,最终具备独立解题的能力。从识别手写数字到预测股票走势,监督学习是当前应用最广泛的机器学习范式。

一、核心原理:输入与输出的映射关系
1. 基本定义
监督学习通过标注数据(Labeled Data)训练模型,每个训练样本包含:
-输入特征(X):描述事物的特征(如房屋面积、楼层、地理位置)
-输出标签(Y):对应的正确答案(如房价、是否患病)
目标:找到从X到Y的最佳映射函数 Y=f(X),使得对新数据能准确预测Y值。
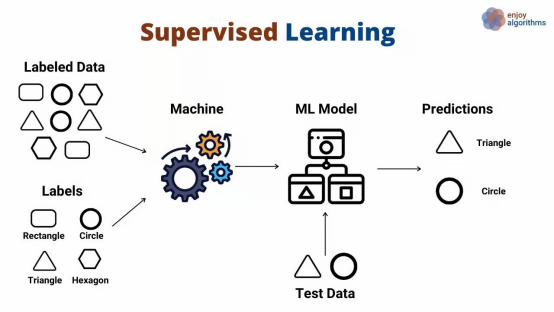
2. 与人类学习的类比
学生:机器学习模型
教材:带有标签的数据集
考试:用测试集评估模型准确率
家教反馈:通过损失函数(Loss Function)告诉模型预测误差
二、两大核心任务类型
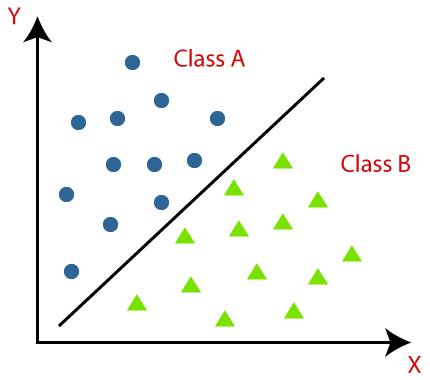
1. 分类(Classification)
目标:预测离散类别标签
经典场景:
– 二分类:垃圾邮件过滤(是/否)、癌症诊断(阳性/阴性)
– 多分类:图像识别(猫/狗/鸟)、情感分析(积极/中立/消极)
输出形式:概率分布(如判定邮件有80%概率是垃圾邮件)
代表算法:
– 逻辑回归:通过S型函数将线性回归结果压缩到0-1之间
– 支持向量机(SVM):寻找最大化类别间隔的超平面
– 随机森林:多棵决策树投票决定最终分类结果
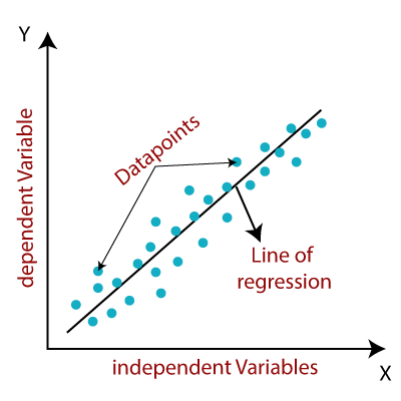
2. 回归(Regression)
目标:预测连续数值经典场景:
– 房价预测、股票价格趋势分析
– 气温预测、用户生命周期价值估算
输出形式:具体数值(如预测明天上海气温为28.5℃)
代表算法:
– 线性回归:拟合一条最接近所有数据点的直线y=wx+b
– 决策树回归:通过特征分割区间计算平均值
– 神经网络回归:用深度网络建模复杂非线性关系
三、监督学习全流程解析
1. 数据准备阶段
数据收集:获取带标签的历史数据(如医院病历库中的“症状–诊断”记录)
特征工程:
– 处理缺失值(删除或填充)
– 特征缩放(标准化、归一化)
– 特征编码(将文字“男/女”转为0/1)
数据集划分:
– 训练集(70%):用于模型学习
– 验证集(15%):调整超参数
– 测试集(15%):最终性能评估
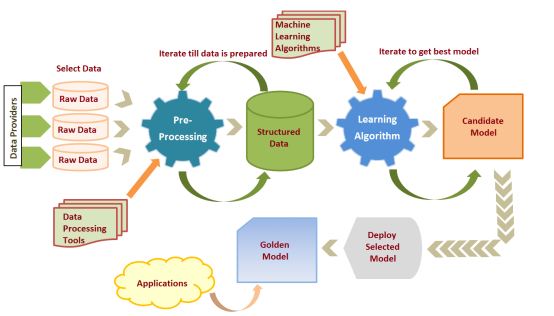
2. 模型训练阶段
选择算法:根据问题类型和数据特点选择(如小数据集可选SVM)
定义损失函数:量化预测误差(如均方误差、交叉熵损失)
优化过程:通过梯度下降等算法调整参数,最小化损失函数
3. 模型评估指标
分类任务:
– 准确率(Accuracy):整体正确率
– 精确率(Precision)与召回率(Recall):针对类别不均衡场景
– ROC-AUC曲线:综合衡量分类器性能
回归任务:
– 均方误差(MSE):预测值与真实值的平均平方差
– R²系数:模型解释数据变动的比例
4. 部署与应用
将训练好的模型封装为API或嵌入应用程序
持续监控模型性能,定期用新数据重新训练(模型迭代)
找华算做计算👍专业靠谱省心又省时!
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
