

如果说监督学习是“老师带学生”,无监督学习(Unsupervised Learning)则更像一场没有地图的探险——机器需要从无标签数据中自主发现隐藏规律,揭示人类未曾察觉的深层联系。它是数据挖掘的核心工具,也是探索未知模式的智能探照灯。
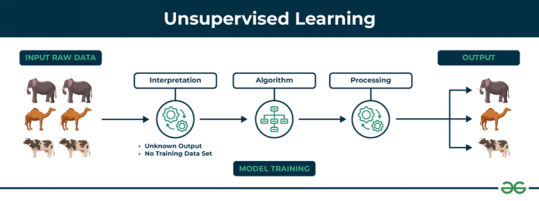

一、核心思想:在没有标准答案的世界里寻找秩序
1. 本质定义
输入:仅含特征(X)的无标签数据
例:用户购物记录(商品列表)、基因表达数据、新闻文章集合
目标:发现数据内在结构,包括聚类、降维、关联关系等
关键特点:没有预设的“正确答案”,算法需要自主定义数据组织方式
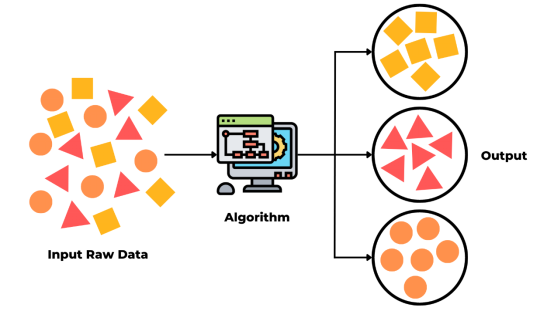
2. 与监督学习的对比
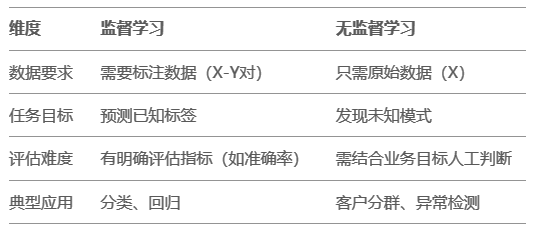
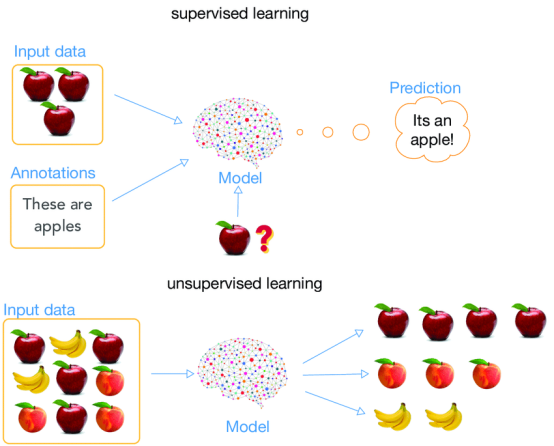
3. 人类认知类比
考古学家:从零散文物中推断古代文明结构
天文学家:通过星系分布发现宇宙大尺度结构
侦探破案:从线索碎片中重建犯罪网络
二、三大核心任务类型
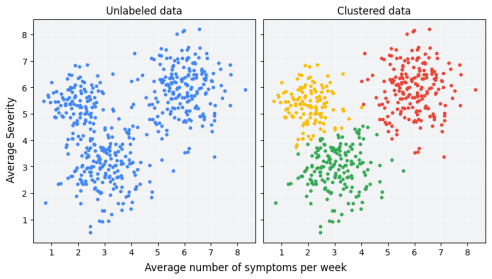
1. 聚类分析(Clustering)
目标:将相似数据归为同一组,不同组差异最大化
经典场景:
-电商用户细分(高价值用户/价格敏感用户/流失风险用户)
-基因表达聚类(发现具有相似功能的基因簇)
-新闻话题挖掘(自动归类相似主题报道)
代表算法:
K均值(K-Means)
-步骤:随机选K个中心 → 分配数据到最近中心 → 重新计算中心 → 迭代至稳定
-可视化:将杂乱彩色点自动分成K个颜色区域
层次聚类(Hierarchical Clustering)
-构建树状结构(树状图),可灵活选择聚类粒度
-例:物种分类时,既能看到“哺乳动物”大类,也能展开到“猫科/犬科”子类
DBSCAN
-基于密度聚类,擅长发现任意形状的簇
-应用:卫星图像中识别城市群轮廓
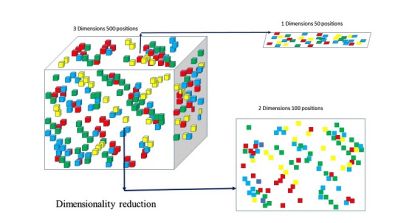
2. 降维(Dimensionality Reduction)
目标:压缩数据维度,保留核心信息
价值:
可视化:将高维数据投影到2D/3D空间
去噪:过滤无关特征提升模型性能
加速计算:减少特征数量降低计算成本
代表算法:
主成分分析(PCA)
-数学原理:通过正交变换找到方差最大的投影方向
-案例:将100维的消费者行为数据简化为3个“核心消费倾向”维度
t-SNE
-擅长保留局部结构,常用于可视化高维数据(如MNIST手写数字投影)
自编码器(Autoencoder)
-神经网络结构:编码器压缩数据→ 解码器重建数据
-可学习非线性降维规则(比PCA更灵活)
3. 关联规则学习(Association Rule Learning)
目标:发现数据中的共生规律
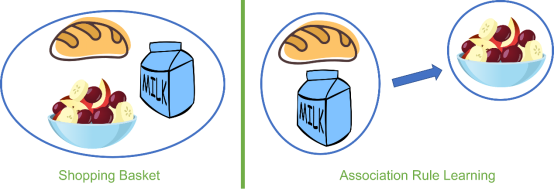
经典应用:
购物篮分析:“买尿布→买啤酒”的关联规则
医疗诊断:症状组合与疾病的关联关系
电影推荐:喜欢A电影的用户常喜欢B电影
代表算法:
Apriori算法
核心思想:频繁项集的先验性质(子集必频繁)
步骤:找出所有频繁项集→ 生成关联规则 → 计算支持度/置信度
FP-Growth算法
改进方法:通过频繁模式树(FP-Tree)减少扫描次数
效率比Apriori提升10倍以上
三、无监督学习的优势与挑战
优势:
✅无需标注数据:直接利用海量原始数据
✅发现未知模式:可能揭示人类未认知的规律
✅灵活适应场景:适用于标注困难领域(如宇宙学、社会学)
挑战:
⛔评估难度大:缺乏客观评价标准(需结合业务解释)
⛔计算复杂度高:尤其在高维数据场景(维度诅咒)
⛔结果不稳定:不同算法/参数可能得出迥异结论
找华算做计算👍专业靠谱省心又省时!
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
