

想象一下,你教一个孩子识别猫和狗:你不会给他写一本《猫狗鉴别公式手册》,而是给他看大量猫狗图片,让他自己总结规律。机器学习算法就是计算机的“学习指南”——它通过分析数据自动发现规律,最终学会完成预测、分类甚至创造性任务。
机器学习算法的三大门派
根据学习方式和数据特点,主要分为三类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、强化学习(Reinforcement Learning)
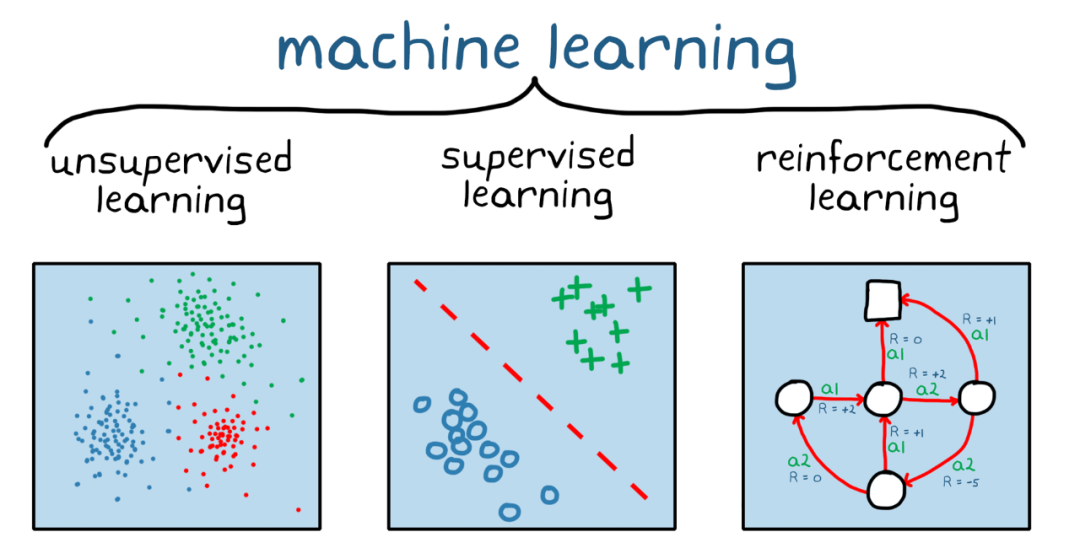

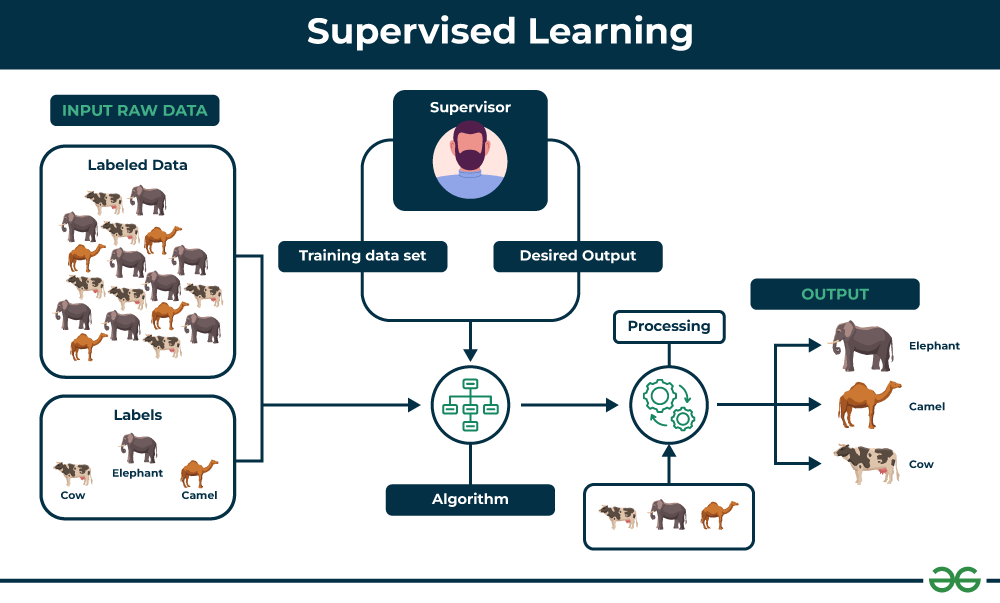
1. 监督学习:像老师带学生做练习题
核心特点:
训练数据包含输入特征+标准答案(标签)
目标:学会从输入到输出的映射关系
经典任务:
分类(输出离散类别):
– 垃圾邮件过滤(判断“是”或“否”)
– 疾病诊断(判断“患病”或“健康”)
回归(输出连续数值):
– 预测房价(输出具体金额)
– 预估气温变化(输出温度值)
代表算法:
决策树:通过一连串“是非问题”做决策,像流程图
例:判断是否批准贷款
神经网络:模仿人脑神经元,擅长处理复杂非线性关系
多层网络可识别图片中的猫:底层学边缘→中层学形状→高层学整体特征
支持向量机(SVM):在数据中画一条最宽的“分界线”区分类别
2. 无监督学习:像探险家发现新大陆
核心特点:
训练数据没有标准答案
目标:发现数据中的隐藏结构或规律
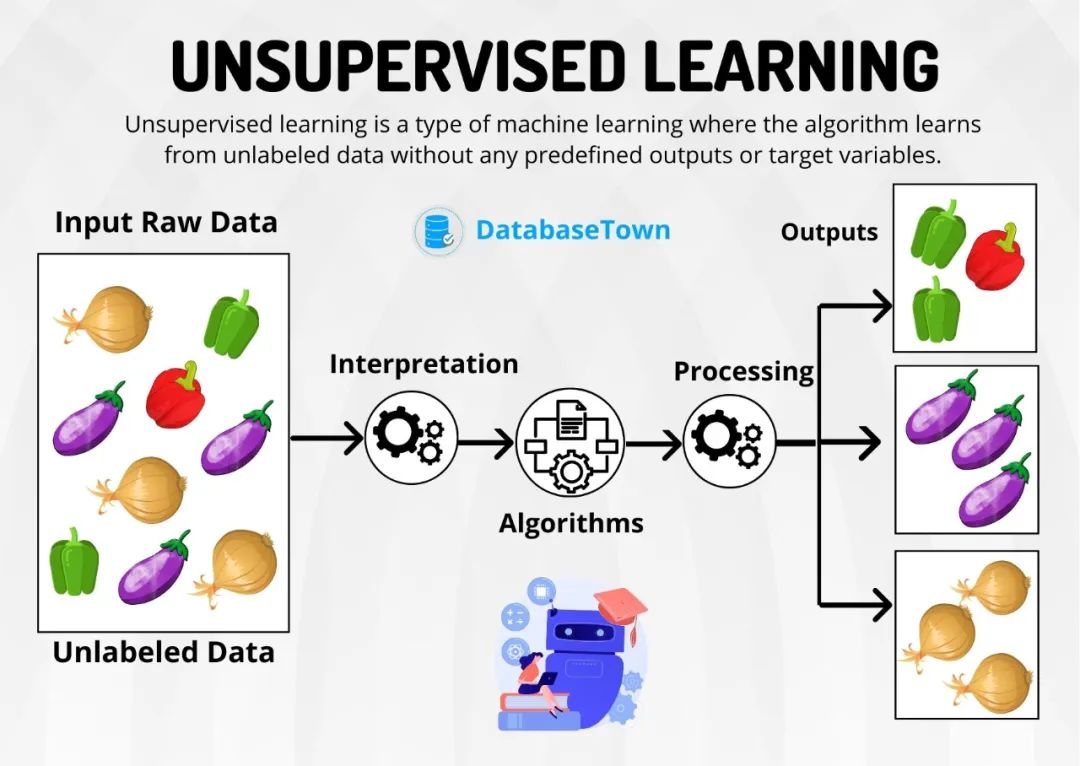
经典任务:
聚类:把相似的数据归为一组
– 电商用户分群(高消费族/低频用户/折扣敏感群体)
– 基因序列分类(发现潜在疾病相关基因簇)
降维:压缩数据维度,保留关键信息
– 将100个特征的用户数据简化为3个核心维度
关联分析:发现数据中的共生规律
– “买尿布的人常同时买啤酒”(经典零售案例)
代表算法:
K均值聚类(K-Means):
– 步骤:①随机选K个中心点 → ②把每个数据点分配给最近的中心 → ③重新计算中心位置 → ④重复直到稳定
– 好比把一堆杂乱纽扣按颜色自动分成K堆
主成分分析(PCA):
– 通过坐标轴旋转,找到最能解释数据差异的方向
– 示例:将3D数据投影到2D平面,保留90%信息量
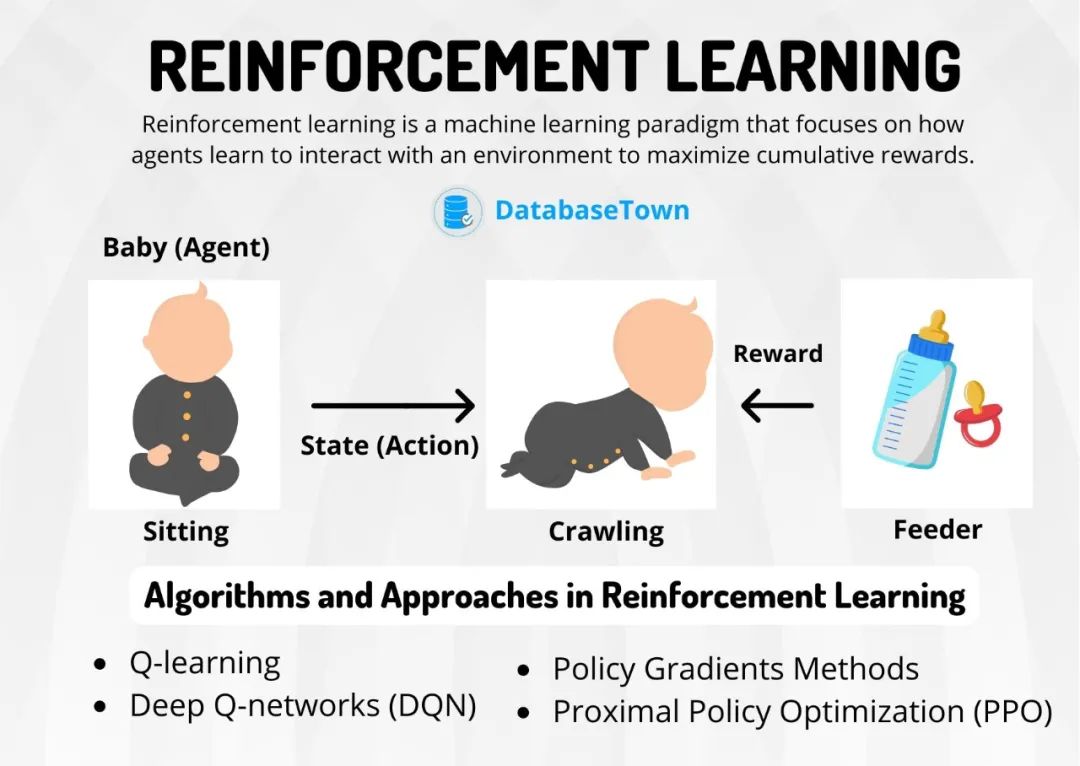
3. 强化学习:像训狗师培养宠物技能
核心特点:
通过试错获得环境反馈(奖励/惩罚)
目标:学习长期收益最大化的行为策略
经典场景:
围棋AI AlphaGo:每走一步棋获得“胜率变化”作为奖励信号
自动驾驶:安全抵达目的地获得正奖励,碰撞获得负奖励
代表算法:
Q-Learning:
– 建立“状态–动作”价值表(Q表),选择预期收益最高的动作
– 例:迷宫导航中,每个位置(状态)对应不同移动方向(动作)的得分
深度强化学习(如DQN):
– 用神经网络替代Q表,处理复杂状态(如游戏画面像素)
益于理论计算化学的快速发展,计算模拟在纳米材料研究中的运用日益广泛而深入。科研领域已经逐步形成了“精准制备-理论模拟-先进表征”的研究模式,而正是这种实验和计算模拟的联合佐证,更加增添了论文的可靠性和严谨性,往往能够得到更广泛的认可。
华算科技已向国内外1000多家高校/科研单位提供了超过50000项理论计算和测试表征服务,部分计算数据已发表在Nature & Science正刊及大子刊、JACS、Angew、PNAS、AM系列等国际顶刊。
